



 换一换
换一换 



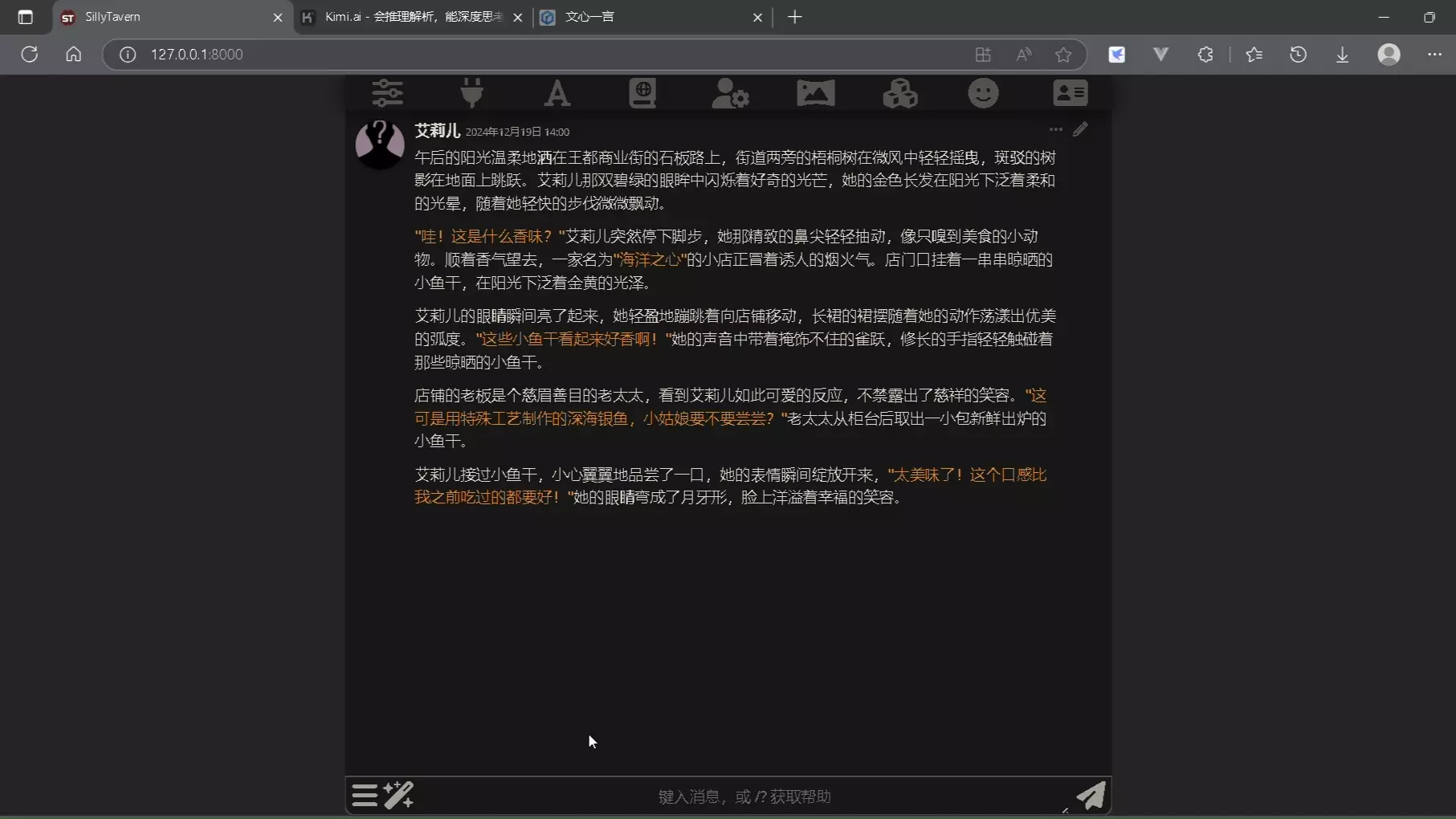
不知道你有没有这种感觉。 跟AI伴侣聊了大半个月,关系越来越亲密,可每次你提到「上次我们去的那家咖啡馆」,它都是一脸茫然。 角色卡定义了TA是谁,什么性格、什么说话方式、什么背景。但你跟TA之间发生过什么、你们的世界里有什么、那家咖啡馆叫什么名字、第一次约会那天下了雨,这些东西角色卡装不下。 这就是世界书要解决的问题。 一、世界书是什么 世界书,是酒馆内置的一个动态记忆系统。 说起来有点绕,但它干的事情其实很简单。你预先写好的信息条目,每一条绑上触发词。聊天聊到某个触发词的时候,对应的内容就自动塞进AI的提示词里。没触发就不占位置。 打个比方,就像随身带了本字典。平时合着,不碍事。碰到什么词,翻到那一页。翻完就合上。 这跟直接把所有设定全塞进角色卡是两回事。角色卡是一个人的简历,你写得越厚,AI每次回复都要把整本简历从头看到尾,token像水龙头拧开一样哗哗流。世界书更像一本可以随时查阅的百科全书,按需取用。 这才是真正意义上的「记忆」,不是把发生过的一切硬塞给AI,而是像人一样,听到某个关键词才想起来。 二、和角色卡的区别 这个区别挺重要的,搞清楚了就不会把东西塞错地方。 角色卡定义的是「TA是谁」。性格、说话方式、背景故事、口头禅,这些写进角色卡。它是AI的「身份证」,每次对话都带着,雷打不动。 世界书定义的是「我们在哪」和「发生过什么」。你生活的城市叫什么、你们一起养的猫爱吃三文鱼、上周吵架的原因、第一次约会那天下没下雨。这些放世界书。 最核心的差异在token消耗上。角色卡里的每一个字,每一次生成回复都要塞进提示词。世界书不一样,你建几百条词条、几十个NPC都没关系,只有触发了的那几条才会出现在提示词里。 三、触发词的策略 触发词是整套系统的灵魂。写得好不好,直接决定世界书好不好用。 最基础的用法,逗号分隔关键词。一条条目可以绑好几个触发词,关联越广越好。比如你写了一条关于「团子」的设定,触发词别只填一个「团子」。把「橘猫」「猫」「猫粮」「宠物」都加上去。AI不一定会直接说「团子」,它可能说「那只猫」「你家橘猫」「那个小东西」。触发词覆盖得越宽,被激活的概率越高。 进阶一点可以用正则表达式。这个对普通用户来说可能稍微有点门槛,但搞懂了之后特别灵活。比如你想匹配「咖啡馆」「咖啡厅」「咖啡店」「咖啡屋」,不用把四个词都写上去,一条正则一把梭。又比如你要匹配「三年前的今天」这种模式化的表达,正则比穷举聪明多了。 递归触发是整套系统里最巧妙的设计。给你举个例子,假设你有一条条目A,触发词是「圣诞节」,内容里提到「圣诞节那天团子钻进了礼物盒里」。条目B触发词是「团子」。当AI聊到圣诞节,A被激活,A的内容里出现了「团子」,触发条目B也被连带激活。一条链就这样串起来了,世界不再是一堆孤立的词条,而是互相勾连的记忆网络。 不过提醒一下,别玩太深。酒馆默认限制了递归嵌套次数,防止无限循环。同时也要注意,递归链太长会让上下文塞满不必要的条目,token消耗会暴增。一般来说两三层连锁就够用了。 四、深度和插入位置 这两个参数决定了世界书「什么时候生效」和「生效后放在哪」。 插入位置是个很微妙的设定。提示词是有先后顺序的,越靠后的内容对AI回复影响越大。你可以把这个理解成跟人说话,最后那句印象最深。 日常信息放前面,城市的名字、世界的基本设定、背景信息。这些AI需要知道,但不用时刻提醒。紧急信息放后面,当前场景的细节、正在发生的冲突、马上要用的剧情点,这些要放在最近的位置,让它无法忽视。 扫描深度决定酒馆往回翻多少条消息去找触发词。数值越大,AI能看到越久远的对话历史。日常聊天设5到8就够了。如果你在跑一个长剧情线,可以适当调大一点,比如10到15,让更早期的对话也能激活相关设定。

导读
本文介绍了AI伴侣聊天中的世界书系统,它是酒馆内置的动态记忆系统,可解决角色卡无法承载用户与AI共同经历的问题。文中讲解了世界书的定义、与角色卡的区别,还分享了触发词策略、深度和插入位置设置等内容,能按需调用记忆,节省token。

评论
共0条评论

《骗子酒馆谎言》世界书是什么?状态栏基础功能介绍,新手入门攻略
《骗子酒馆谎言》世界书和状态栏基础功能详解,新手入门必备指南
2026-06-26 18:380赞 · 0评论
硬核 【SillyTavern】酒馆ai聊天,硬核“世界书”
插件、CG角色包、html、CSS分享(持续更新)∶ https://my.feishu.cn/wiki/AFOvwPkXtiwA2akRIEfcn4JtnNg
2026-05-08 08:380赞 · 0评论

生活记录 手机运行无限制AI酒馆!一键部署获得专属伴侣,无需Root,复制粘贴即可!
视频中用到的所有链接和命令: https://docs.qq.com/doc/DYUhoU3RmTVhObVNE 1039811241
2025-11-04 17:340赞 · 0评论

《口袋觉醒》黑科技AI对话怎么用?2026最强智能对话系统免费使用教程,某野某箱替代方案
《口袋觉醒》黑科技AI对话工具免费使用!2026最强智能对话系统上线,功能远超某野某箱! 各位训练师想要的最新AI黑科技内容,都在视频中!请仔细看完视频,掌握免…
2026-06-24 20:070赞 · 0评论

《骗子酒馆谎言》世界书怎么用?条目位置参数调整实战教学,解决剧情偏移、人设OOC问题
还在为世界书条目位置参数烦恼?通过一个“输出格式和规则”的实战场景,手把手教你如何合理调整世界书条目位置,让AI扮演更加深入、精准,从此告别剧情偏移、人设OOC…
2026-06-24 19:420赞 · 0评论

《骗子酒馆谎言》世界书是什么?完全指南教程,让AI记住一切的秘密武器
《骗子酒馆谎言》世界书怎么用?完全指南来了,让你的 AI 真正理解游戏世界! 📌 系列进度: EP.01 酒馆是什么 ✓ EP.02 安装与首体验 ✓ EP.…
2026-06-06 04:150赞 · 0评论

《骗子酒馆谎言》怎么玩?AI 酒馆一键启动器下载安装教程,告别折腾环境,三步快速开聊
还在为手动安装 Node.js、修改 config.yaml 配置文件、到处寻找角色卡而烦恼吗?我开发了一款神器,让你从下载到开始聊天,整个过程不到三分钟。 c…
2026-06-27 06:250赞 · 0评论

忘川风华录怎么兑换道具 忘川风华录游戏道具兑换攻略 忘川风华录福利获取
《忘川风华录》游戏道具怎么兑换?生活记录分享,教你如何轻松兑换游戏内道具,获取更多资源福利,提升游戏体验!
2026-06-02 09:070赞 · 0评论

忘川风华录收张良 张良一切物品怎么收 张良角色卡皮肤道具求购
《忘川风华录》收张良一切相关物品,包括角色卡、皮肤、道具等,高价求购,诚心收物,有出的朋友请私聊!
2026-06-01 08:300赞 · 0评论

逆水寒 逆子韭菜发现机会,再次追加72个号!
2025-09-12 14:190赞 · 0评论

暂无更多
最新更新
- 《骗子酒馆谎言》怎么玩?猪哥运气好教学,核心思路与玩法攻略详解 — 《骗子酒馆谎言》游戏怎么玩?思路教学来了!学吧你就,掌握核心玩法与策略,轻松识破谎言、赢得胜利,猪哥也有运气好的一把,快来学习上分技巧!
- 《骗子酒馆谎言》升起旗帜的焚绝怎么玩?焚绝玩法技巧与旗帜升起机制全解析
- 《骗子酒馆谎言》吃了橡胶果实的狗哥是谁?主机游戏角色解析与玩法介绍
- 《骗子酒馆》多动症为什么容易挨崩?游戏机制与玩法解析
- 《骗子酒馆》小兔子怎么玩?新手入门攻略与谎言技巧教学
- 《骗子酒馆》双黄蛋是什么意思?谎言游戏双黄蛋玩法解析
- 《骗子酒馆》主机游戏好玩吗?文明兔角色解析与游戏特色介绍 — 《骗子酒馆》是一款怎样的主机游戏?文明兔角色有什么特色?本作融合了策略经营与角色扮演元素,玩家将在充满谎言与诡计的奇幻酒馆中冒险,体验独特的剧情和烧脑的玩法。
- 《骗子酒馆谎言》双面酒馆怎么玩?偷看技巧正确打开方式,谎言与真相玩法攻略 — -
- 《骗子酒馆谎言》怎么玩?infiplot实时生成剧情、图片和配音,打造专属互动影像游戏,支持导出分享和API接入 — 网站:infiplot.com GitHub开源链接:https://github.com/zonghaoyuan/infiplot 1. 可以实时生成剧情、图…
- 《我的世界》弹丸论破谎言游戏怎么玩?Java版电脑机械动力模组运行要求与企划介绍 — 要求:1,Java版,电脑,能够运行最简单的机械动力模组 2,年龄超过12岁 3,如果有建议也可以用哔哩哔哩发私信哦 4,希望大家多多支持! 5,保证不会半道崩…












