换一换
换一换 





多线程设置指南 本次更新中,我们对多线程系统进行了彻底重建,并为玩家提供了多种自定义线程策略的选项。这些选项可通过以下途径调整: 1. **[深度分析器]**(从性能测试(CPU)中进入,点击[深度分析]按钮) 2. **[设置]-[游戏性]** 下的高级多线程设置 在测试阶段,许多玩家对如何配置多线程系统感到困惑。下面为大家分享一些常用的设置方案: 对于不想进行过多调整的玩家,默认设置通常即可满足需求。不过,如果默认设置导致卡顿,你可以尝试以下配置: ● **主线程绑定策略**:系统自动分配 ● **工作线程绑定策略**:可使用任何可用核心 ● **线程帧等待策略**:混合等待 ● **线程阶段等待策略**:混合等待
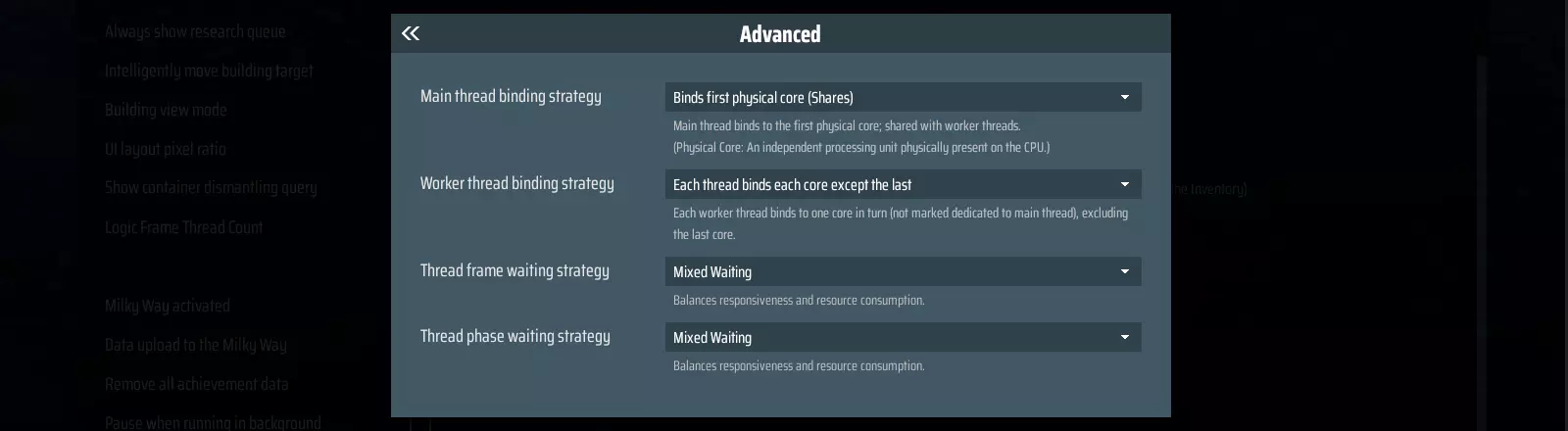
此设置具有高度的通用性,适用于大多数情况。 现在让我们来看看一些更高级的设置方案: 标准架构:指没有性能核心与能效核心之分的CPU。 若你追求更出色的游戏性能,可以尝试: ● 主线程绑定策略:绑定第一个物理核心(共享) ● 工作线程绑定策略:每个线程依次绑定每个逻辑处理器 ● 线程帧等待策略:混合等待 ● 线程阶段等待策略:混合等待

如果你经常同时运行多个应用程序,且需要为它们预留性能,可以尝试以下策略: ● **主线程绑定策略**:绑定第一个物理核心(共享) ● **工作线程绑定策略**:每个线程绑定除最后一个核心外的各个核心 ● **线程帧等待策略**:混合等待 ● **线程阶段等待策略**:混合等待
混合架构:指区分性能核心与能效核心的CPU。 若你追求更优游戏性能,可尝试: ● 主线程绑定策略:绑定首个性能核心(共享) ● 工作线程绑定策略:每个线程依次绑定每个性能核心或两个能效核心 ● 线程帧等待策略:混合等待 ● 线程阶段等待策略:混合等待
如果你经常同时运行多个应用程序,且需要为它们预留性能,可以尝试以下策略: ● **主线程绑定策略**:绑定首个性能核心(共享) ● **工作线程绑定策略**:每个线程绑定除最后一个外的各个核心 ● **线程帧等待策略**:混合等待 ● **线程阶段等待策略**:混合等待

以上是通用设置,但根据您的硬件配置,实际性能可能会有所不同——这些设置并不能保证达到最佳效果。 当然,对于希望进行微调并找到最适合自己策略的硬核玩家,我们还开发了自定义核心绑定功能。该功能允许玩家为每个单独的线程配置CPU核心绑定策略。 您可以在高级多线程设置中找到此功能。将线程绑定策略设置为“自定义核心绑定”后,您就能修改每个线程的绑定了。
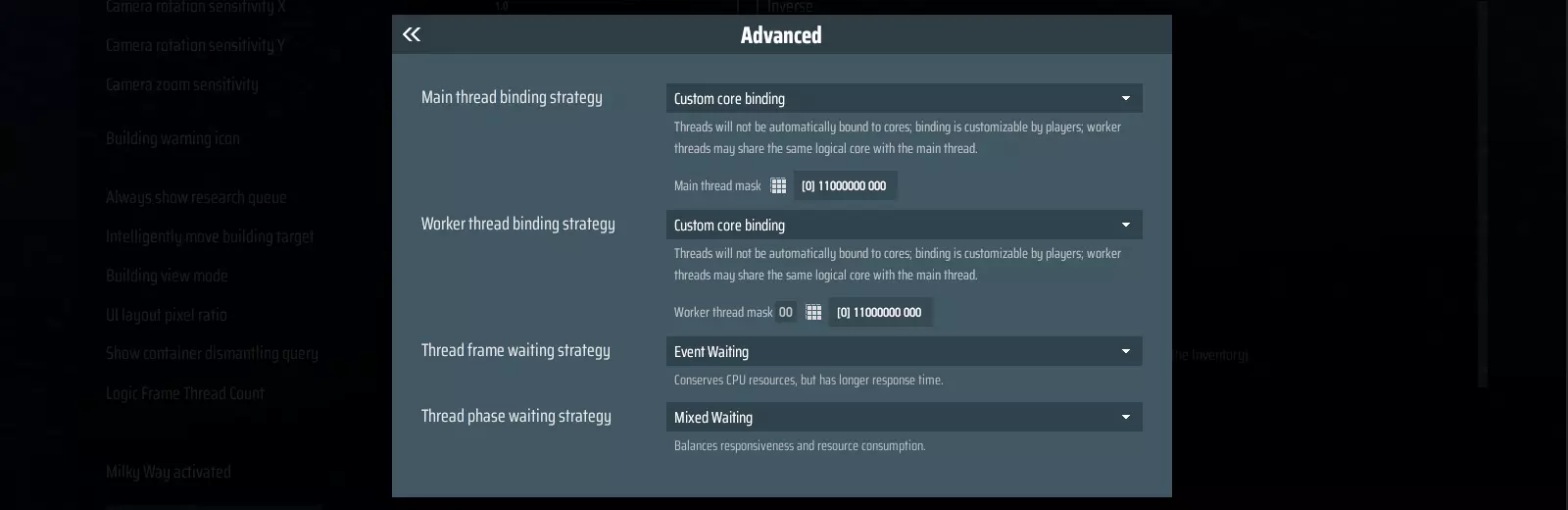
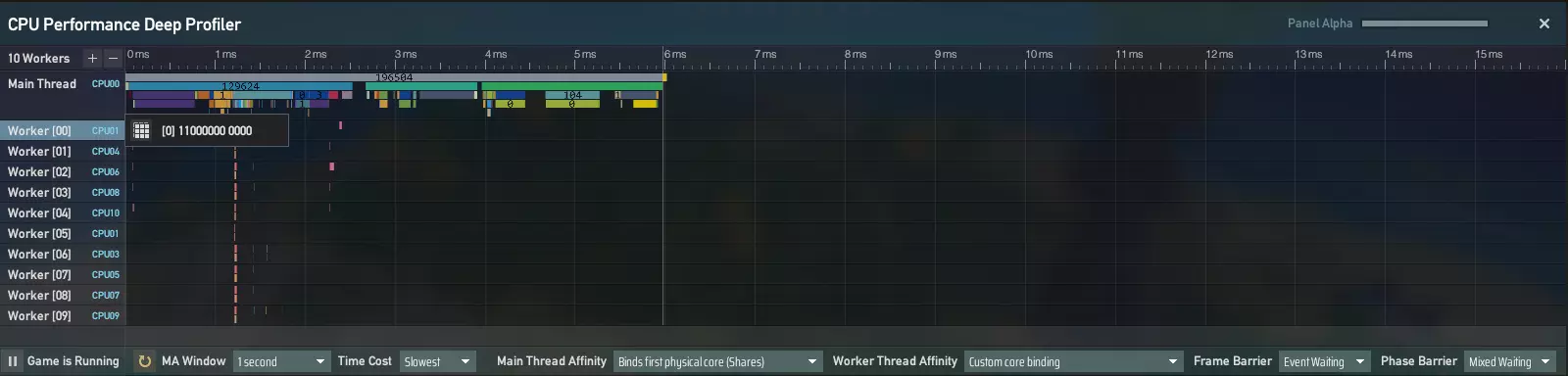
例如: 工作线程掩码 00 表示你正在编辑工作线程 00 的设置。[0] 11000000 0000 是掩码。[0] 是线程组(通常设为 0,除非线程数超过 64)。 其后的二进制掩码表示此线程的逻辑处理器:1 表示可在此处理器上运行,0 表示不可。 在此示例中,工作线程 00 允许在第一和第二个逻辑处理器(CPU0 和 CPU1)上运行,但不允许在其他处理器上运行。 也可通过【深度分析器】访问此配置,方法是点击每个线程进行设置。
对于希望进一步了解各选项的玩家,我们在高级多线程设置中还为每一项设置都添加了详细说明。玩家可以在尝试配置时参考这些说明。 技术概述 在以往的开发和维护过程中,我们认为程序性能已达到极限。如果未来实装载具系统,游戏可能需要额外模拟数千个组件,这远远超出旧多线程系统的承载能力。旧的多线程系统在设计上存在一些重大缺陷:它支持的任务类型非常少,每个阶段的同步开销都很高,而且将逻辑拆分为强制多线程通常几乎带不来性能提升,同时还会增加高昂的维护成本。仓促地将逻辑转换为多线程可能只会带来微不足道的性能改进,却会显著增加代码复杂度。 这就是为什么我们最近对《戴森球计划》的多线程系统进行了彻底的 overhaul,为即将推出的载具系统铺平了道路。以下是这个全新系统的主要特性详解。 1.可自定义核心绑定:在旧系统中,线程由操作系统自动分配,这种“黑箱”机制常导致CPU利用率低下。现在,玩家可以手动将线程分配给核心,从而消除因系统调度造成的性能浪费。

(多线程策略自定义面板) 2.动态任务分配:任务现在会在各线程间平均分配,当某个线程完成其任务份额后,可协助处理其他线程的任务,直至工作负载达到平衡。
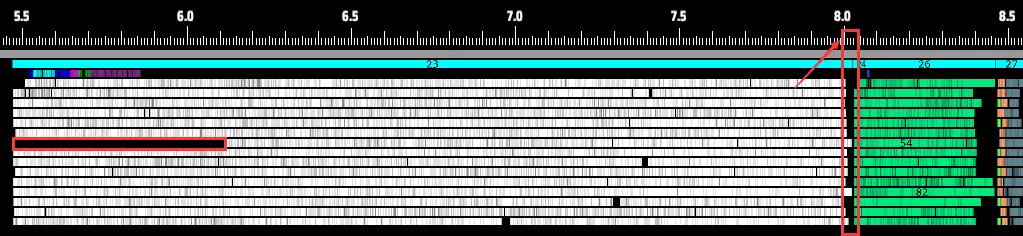
(即使某个线程启动较慢,现在几乎所有线程都能同时完成) 3.更灵活的框架设计:我们不再局限于“每个多线程阶段一种任务类型”。相反,逻辑可以分解为多个任务并灵活组合,实现“每个阶段多任务”。这一灵活框架允许: - 并行运行多个任务; - 将此前锁定在主线程的逻辑转移到其他功能的逻辑中; - 将不可分配任务与可分配任务配对,更好地利用闲置CPU周期。
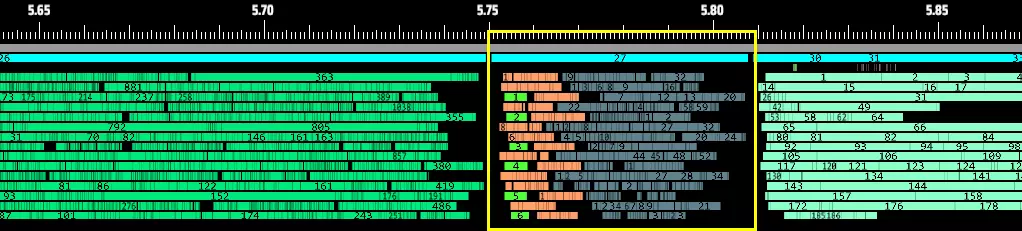
(流量监控器、喷雾器和物流站的传送带输出并行运行时,现在总耗时不到0.1毫秒) 4. 多线程通信与等待机制:新系统采用速度更快的自旋锁(约10纳秒)来链接任务,并结合自旋-阻塞混合模型:极短执行时间的任务使用自旋锁;CPU密集型的长任务使用阻塞锁。这最大限度地减少了一个任务结束到下一个任务开始之间的响应延迟。

(新的多线程等待时间<左侧>明显短于旧系统<右侧>) 5.全新性能分析工具:由于游戏核心逻辑已完全重构,可允许多种任务类型并行运行,我们还开发了全新的性能分析工具。该分析工具能清晰展示新逻辑的运行方式及其效率。
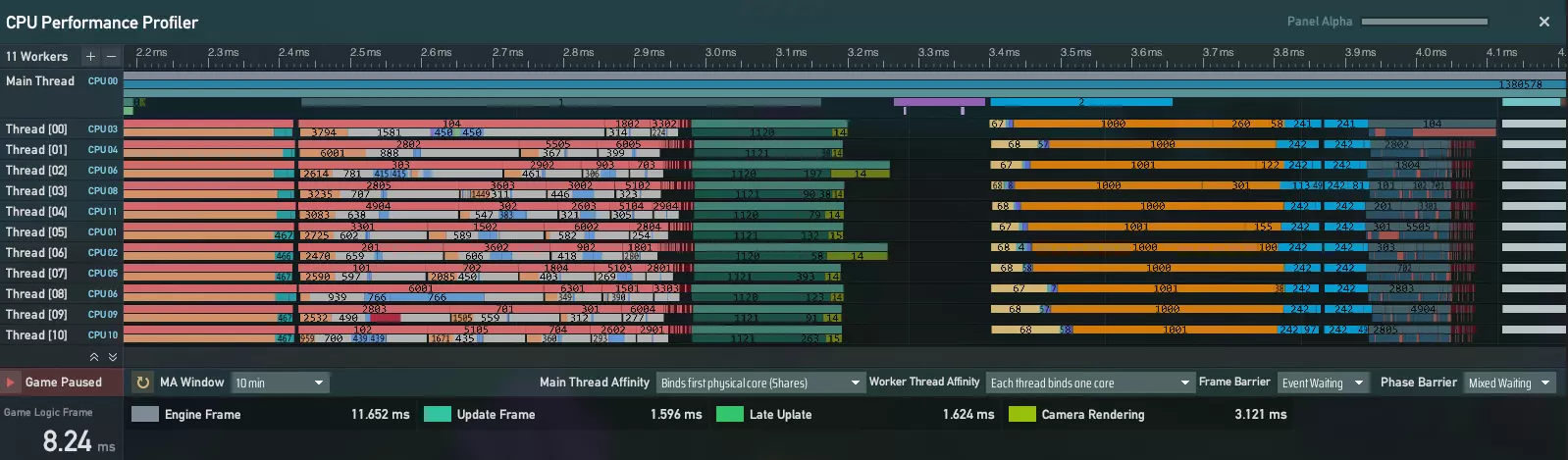
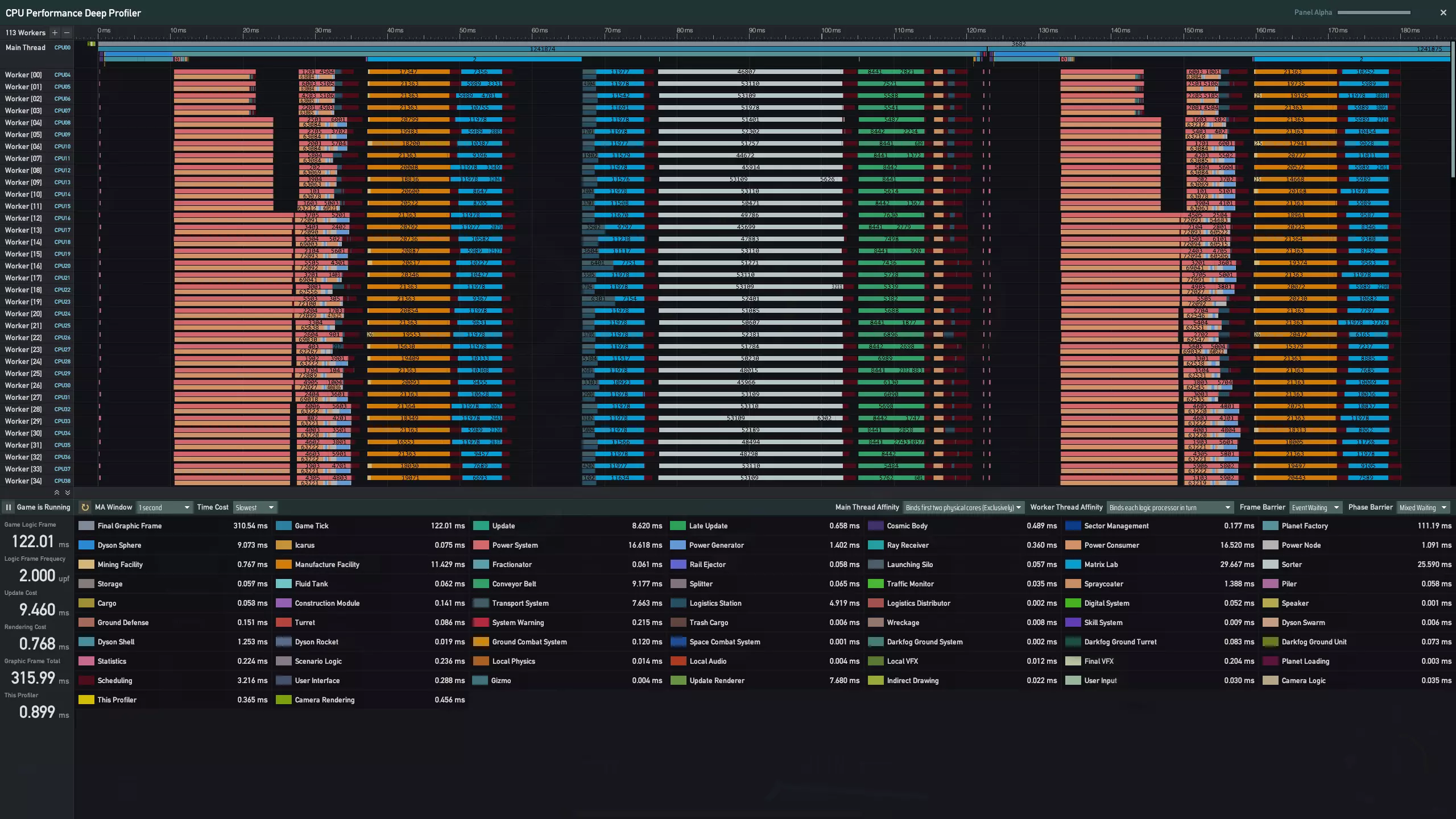
以上是深度分析器的界面:横轴代表游戏运行时间。每行对应特定线程每帧的工作负载。此工具可帮助玩家实时了解其CPU的内部运行情况。 上述内容节选自我们早期关于多线程系统更新的开发日志。更多详情,可在此处查看。
game_id1366540

在游戏社区中,你永远不知道玩家会带来怎样的惊喜。在公开测试期间,有位玩家在Threadripper CPU上运行了《戴森球计划》的多线程版本,着实让我们震惊! 这不仅令人惊叹,还为我们带来了宝贵的反馈:我们的游戏似乎不支持超过64线程。我们迅速定位并修复了这个“幸福的烦恼”。 但故事并未就此结束!面对如此高端的硬件,我们遇到了另一个问题——我们团队没有这样的“神级”设备来进行测试。于是,我们做了一个大胆的决定:厚着脸皮询问这位玩家是否可以“借用”他的CPU性能进行一轮基准测试。
(680W宇宙矩阵存档性能表现) 从截图来看,该游戏与消费级CPU相比没有太大差异。经过一番探查,我们找到了原因:玩家的内存为DDR4-2666。瓶颈很可能出在内存上! 那么关键问题来了:我们该如何进一步优化?又该使用什么平台来验证这些优化效果呢? 正当我们一筹莫展时,我们联系了AMD。令人欣喜的是,他们慷慨地为我们提供了一台性能猛兽:Threadripper PRO 9985WX系统! 单是配置就足以令人激动:64核128线程;基础频率3.2GHz,加速频率最高可达5.4GHz;支持多达8个内存通道。这正是为我们量身打造的终极测试平台!很遗憾,由于台风导致的延误,这只怪物仍在运往我们这里的途中。请和我们一起耐心等待开箱时刻!

一旦“野兽级”硬件上市,我们将立即对这一极致硬件展开深度优化与测试。如果你是线程撕裂者(Threadripper)的用户,请保持关注——我们为你准备的优化即将到来!(当然,消费级CPU也将获得性能提升。) ### 注意事项与常见问题 **Q:遇到bug该怎么办?** **A:** 如果你遇到bug,请首先确保你的游戏处于纯净(未安装模组)状态。建议移除所有模组并重启游戏后再次检查。 如果在纯净环境下bug仍然出现,请在我们的Discord服务器#bug-report频道中进行报告。我们的团队将尽快查看并解决这些问题。 **Q:旧存档能否与新的多线程系统无缝兼容?**A:是的。旧存档可以直接在新版本中加载,无需重新开始游戏。但我们仍强烈建议在更新前备份您的文件,以防万一。 默认存档位置(若未更改): %USERPROFILE% Documents Dyson Sphere Program Save Q:我现有的Mod还能继续使用吗? A:由于本次更新彻底重构了游戏的核心逻辑,代码改动较大,大多数Mod将与游戏本体产生冲突。 如果您一直在使用Mod,我们强烈建议在更新前备份您的存档和Mod。此外,确保更新过程中您的游戏文件未被修改,否则可能会出现意外错误。 Q:我能期待什么样的性能提升?如何能感受到?A:主要改进在于CPU的“游戏逻辑帧”时间。正如开发者日志所示,逻辑帧性能有显著提升。如果你的存档包含大型工厂或激烈战斗场景,差异会更加明显。 Q:调整多线程设置后,游戏感觉更卡顿了怎么办? A:首先,尝试将所有设置恢复为默认值(包括逻辑帧与渲染帧之间的比例)。你也可以查看我们的设置指南以获取更多选项。如果希望获得更好的性能,可以加入我们的官方Discord服务器,与其他玩家和管理员讨论,为你的硬件找到最佳配置。 Q:为什么更新后逻辑帧的执行时间看起来比更新前更长?对于那些运行已经非常流畅的存档(逻辑帧执行时间低于5ms),新系统下显示的数值可能会略高一些。但只要数值保持在5ms左右,实际游戏体验不会有任何差异。真正的改进体现在负载较重的情况(当逻辑帧降至60 FPS以下且执行时间超过8ms时),在这些情况下,新系统能带来显著提升。