



 换一换
换一换 




本指南将聚焦于模组制作的基础:《征服伊洛希姆4》的模组由哪些电脑文件构成,以及如何在电脑上创建和编辑这些文件。 最初产生编写此类指南的想法,是因为我看到许多模组制作者在创建用于模组旗帜的TGA图像文件时遇到困难。我本打算只写一个简单的“制作你自己的旗帜”指南。后来,当我发现《征服伊洛希姆4》支持文本文件中的UTF-8编码时,我意识到许多模组制作者可能也需要这方面的帮助和解释——至少在Windows和Mac用户中是这样,因为在这些系统上,UTF-8的普及程度仍不及Linux。或许完整的指南有些冗长,但并非所有人都需要从头读到尾。你只需挑选自己感兴趣的部分阅读即可。 本指南不会教你如何创建自己的《征服伊洛希姆4》新职业,也不会列出所有可用的模组命令——这些内容会有专门的模组手册介绍。这里仅涵盖两个最基础的模组命令,即每个模组都必须包含的命令,同时还会解释如何在模组中使用特殊字符。 什么是模组? 模组是一种用于更改或增添游戏某些方面内容的方式。它由一个纯文本文件(文件名应以“.c4m”结尾)和一张256×64像素的TGA格式图片文件(即横幅,用于在菜单中展示模组)组成。图像必须保存为RGB格式,可包含或不包含alpha通道(包含时为32位/像素,不包含时为24位/像素)。它可以进行RLE压缩。 准确来说,图像尺寸似乎可以是任意大小,游戏会对图像进行缩放以适应。不过,若想所见即所得,至少应确保宽度是高度的四倍。此外,虽然稍大的尺寸可能在高分辨率屏幕上呈现出略多的细节,但显然存在一个临界点,超过该点后,更大的图像尺寸只会浪费空间。 游戏也支持SGI图像格式,但由于这是一种较为罕见的格式,在此假设仅使用TGA图像。 透明度 TGA图像可以存储“alpha通道”,用于标记像素的透明度程度。(阿尔法值为255表示完全不透明,阿尔法值为0表示完全透明。)游戏会利用这一特性。 当图像存储时没有阿尔法通道,游戏会将任何黑色像素(RGB值0,0,0)视为完全透明,将任何亮品红色像素(RGB值255,0,255)视为半透明黑色(用于游戏中的精灵阴影)。这显然会减小图像文件的大小。 如果您不使用任何透明度(或仅使用前段所述的简单透明度),请不要保存带有阿尔法通道的图像。首先“合并图层”或移除阿尔法通道,否则只会浪费空间。 位置? 旗帜最好放在mods目录的子目录中。在上面的示例中,我有一个名为my_new_mod的子目录,其中放置了一个banner.tga文件。当你为你的模组添加更多图像时,这一点就变得尤为重要。如果每个模组都将其图像随意存放在主模组目录中,会造成非常混乱的局面,所以不要这样做。 如何操作? 制作TGA图像无疑有很多方法。不过,如果你确实在问这个问题,我建议你尝试使用GIMP,它是一款跨平台、免费且开源的软件。在接下来的章节中,我会介绍使用GIMP进行操作的基础知识。(如果你已经有其他常用的图像编辑器,可以跳过这部分内容。) 在GIMP中创建TGA图像 ❶ 首先,从文件菜单中选择新建...可能还会有其他TGA图像文件。 当在网络上发布(上传和下载)模组时,模组应以ZIP压缩包的形式提供,其中c4m文件需放在压缩包的根目录下,其余文件则放在一个(具有合适名称的)文件夹中。这样用户只需将ZIP文件解压到其模组文件夹,所有文件就能自动放置到正确位置。与其他压缩文件格式不同,ZIP格式可被所有现代操作系统直接处理,无需额外软件。 c4m文件 扩展名为“.c4m”的纯文本文件应放置在模组目录中。你可以通过以下步骤找到该目录:❶启动游戏,❷选择【模组】,❸选择列表底部的【打开模组目录】。在c4m文件中,你需要编写模组命令来实现所需的修改和添加,每个命令单独占一行。不过,有两个命令是必须存在的:icon和description。例如: icon "my_new_mod/banner.tga" description "这是我的新模组。^^这是两行新内容之后的文字。" icon命令所提供的文本字符串是指向模组横幅图像的相对文件路径。在这个示例中,横幅位于mods的子目录my_new_mod中,文件名为banner.tga。 注意,文件夹和文件名称之间使用正斜杠(/)分隔(类似于Unix系统和互联网URL路径),而非Windows系统中使用的反斜杠(\)。 此外,建议你的文件(和文件夹)名称仅使用小写字母,以避免在Linux系统上出现问题。在Windows系统中,文件名大小写是否一致并不影响使用——如果你将文件命名为“Banner.tga”,但在模组中却以“banner.tga”引用它,仍然可以正常运行。但在Linux系统中,大小写是有区别的,这种情况就无法正常运行。如果只有一个旗帜文件,出现不一致的风险还比较小,但如果有大量的精灵文件,就很容易在某些地方忘记使用大写字母。 使用描述命令给出的文本字符串,会在你或其他模组用户右键点击模组列表中的该模组时显示(在游戏中按F6调出的列表中也会显示)。 文本字符串中不能使用实际的换行符。不过,当游戏显示文本时,字符^(ASCII circumflex)会被替换为换行符。重要的是,所有引用文本字符串(和/或注释;见下文)之外的内容,以及双引号本身,都必须是纯ASCII文本,否则游戏将无法将这些文本识别为命令。换句话说,必须使用这种引号:",而不是更花哨的“或”。 在ASCII引号内的文本中,通常可以包含非ASCII字符。但明显的例外是,那些供游戏程序读取而非供玩家阅读的字符仍必须始终是ASCII。例如用于换行的^符号。其他例子包括addstring命令(在仪式定义中)的文本字符串中的运算符字符,或reclimiter命令(在某职业的招募定义中)中的运算符字符。尽管这些字符用于字符串中,但也必须是ASCII。如果您确实使用非ASCII字符,还需要考虑一些其他因素,我们在深入探讨纯文本概念时会回过头来讨论这些。 使用#字符,您可以将该行剩余部分标记为注释,游戏会完全忽略这些内容。即使在编写模组时您对自己所做的一切都很清楚,但当您以后想要对其进行某些修改时,注释会非常有帮助。当然,注释对其他阅读模组的人也会有所帮助。例如:# 这是一条注释,游戏在解析模组时会忽略它。 彩色文本编辑 有些文本编辑器提供突出显示各种编程语言语法的选项。如果您使用的编辑器恰好具备此功能,您可以尝试将模组文本标记为Unix shell脚本。(寻找一个类似“shell”“sh”或“bash”的选项。)《神域征服4》的模组当然不是Unix shell脚本,但注释的工作方式是相同的,编辑器可能会将注释与命令以不同颜色显示,字符串文字也可能以第三种颜色显示。 关于换行符和Windows记事本的说明:如果你曾在Windows记事本中尝试加载Illwinter的示例模组,可能会发现换行符显示异常。这是因为Unix系统(包括Linux和现代Mac)与Windows系统对换行符的表示方式不同。在Unix系统中,每个换行符都是单个ASCII字符,其数值为10(也称为LF或换行);而在Windows系统中,换行符是两个ASCII字符的序列,即13和10(其中第一个字符也称为CR或回车)。 Windows系统的这一约定可追溯至DOS和CP/M,最终源于20世纪60年代(甚至更早)DEC大型机上使用的软件。(使用两个字符是为了给电传打印机的打印头从最右侧物理返回到下一行开头留出更多时间。)在Unix系统(最早是Multics)中,设备驱动程序的新概念使应用程序能够忽略电传打印机硬件的复杂细节,因此可以使用更简单的单字符编码来表示换行。(当然,这一切都发生在视频终端时代之前,更不用说个人电脑了。) 应当说明的是,如今大多数文本编辑器,无论运行在哪种操作系统上,都能识别这两种换行符。尽管《征服伊旬园3》的手册推荐使用Unix换行符,但在我看来,《征服伊旬园3》和《征服伊旬园4》其实都能很好地识别Windows换行符。在Windows系统中,记事本无法识别Unix换行符的情况相当特殊,而且出于一些我们稍后会提到的原因,记事本也不是Windows系统下进行《征服伊旬园4》模组制作的最佳选择。不过不用担心,在关于Windows系统纯文本的章节中会提供解决方案。 横幅 横幅是一个TGA(也称为TARGA)图像文件,其尺寸应为256×64像素。
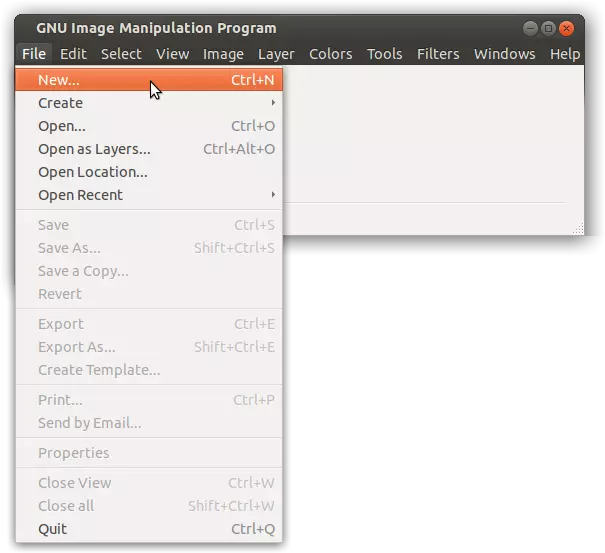
将图像尺寸设置为宽度=256,高度=64。
③ 为图像填充一些内容。(我知道这一步描述得比较简略,但稍后我会对这个主题展开详细说明。)
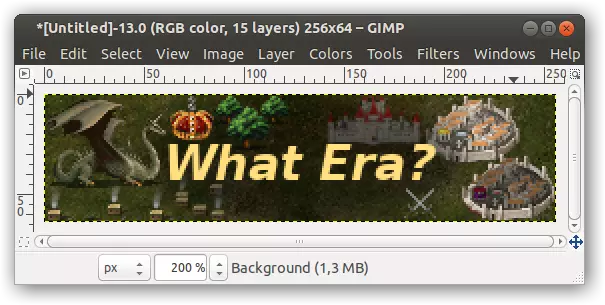
4. 从文件菜单中选择【导出为...】(保存选项用于保存XCF文件,这类文件适用于图像编辑项目,因为它们可以包含多个图层、路径以及其他最终图像中不需要的内容。)
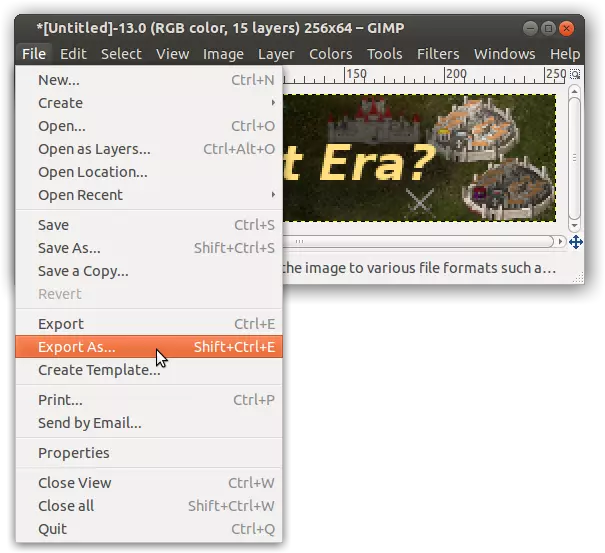
导航至你的子目录下的mods文件夹(在我的示例中为my_new_mod),并输入文件名banner.tga。你也可以使用其他文件名,只要以“.tga”结尾即可。然后点击导出。
TGA导出的默认设置应该没问题。只需点击导出即可。
GIMP 图像编辑基础 基本布局 当然,GIMP 的功能太多,我无法一一介绍,而且我本身也不认为自己是 GIMP 专家。我只提一些需要记住的基本要点。 启动 GIMP 时使用默认布局,中间会出现一个带有菜单的图像主窗口,另外还有两个面板分别位于各自的次要窗口中,左右各一个。此布局高度可配置——例如,可以通过“窗口”菜单中的选项切换到单窗口模式(需要重启 GIMP 才能生效)——但这里我假设使用默认布局。 可以使用 Tab 键(↹)来切换面板的显示和隐藏。我得承认,偶尔(不小心按到Tab键后)面板会消失,这起初让我很困惑,但这么设计的目的是为了能快速查看扩展图像窗口中原本被遮挡的部分。如果按了Tab键后还是找不到面板,你可以在窗口菜单→最近关闭的停靠面板中找到它。 工具箱
左侧面板即工具箱,首先包含用于创建选区(限制图像中可编辑或复制等的部分)的各种工具,最后是用于编辑图像的工具,两者之间还有一些其他工具。选择每个工具时,窗口下方会显示多个选项。 工具图标下方是前景色/背景色指示器。这些颜色(默认是黑色和白色)会影响部分工具和选项的工作方式,点击它们可以更改颜色。 在此示例中,已选择文本工具。你可能会想用它在横幅上写下你的模组标题。 请注意,要移动文本,你需要切换到移动工具。
只要文本图层处于激活状态(见下文),你就可以使用光标键移动文本。或者,无论哪个图层处于激活状态,只要你点击文本(某个可见的字符部分),就可以用鼠标将其拖到你想要的位置。如果你之后再次选择文本工具,可以点击文本进行更多编辑。 图层
第二个面板显示图像的图层。(默认情况下,它还包含通道、路径和撤销历史记录的选项卡。)使用刚才提到的文本工具会自动为文本添加一个单独的图层。从其他地方复制的图像(例如某些图像查看器应用程序)也可以作为它们自己的图层粘贴到你的图像中。(如果你在GIMP中打开了多个图像,可以直接在它们之间拖放图层。)当然,在图层面板中右键单击时,添加新图层是给出的选项之一(底部也有一个用于此操作的按钮)。 在合成图像中,顶层图层会遮盖其下方的图层,但透明区域(或者如果图层小于图像,则是它们未覆盖的部分)除外。可以通过拖放来更改图层顺序。 如果图层名称以粗体显示(例如示例中的背景图层),则该图层没有 alpha 通道(即完全不透明)。如果名称不是粗体,则图层具有 alpha 通道(即可以部分或完全透明)。在有 alpha 通道的图层中擦除的部分将变为透明,而在没有 alpha 通道的图层中擦除的部分将填充当前选择的背景色。
左侧的眼睛图标表示该图层可见且会用于合成图像。点击眼睛图标可切换图层的显示状态。点击眼睛图标旁边的位置,会出现一个链条图标。
如果有两个或更多图层标记了链条图标,那么对其中一个图层进行某些操作(移动、旋转等)时,所有标记链条图标的图层都会受到影响。 图层上方是锁定按钮,启用后将分别防止编辑整个图层或仅其 alpha 通道。(alpha 锁定允许你编辑可见部分的颜色,而不会影响透明区域的边界。)遗憾的是,在撰写本文时,用户界面存在一个小 bug,导致这些按钮的停用状态要等到你从图层对话框切换到主窗口或其他窗口后才会显示。如果你知道这个情况就没什么大不了,但否则可能会有点混乱。 我认为一个常见的新手错误是没有留意当前激活的是哪个图层。如果你进行的某些编辑操作似乎没有任何效果,不要因为工具“没反应”就疯狂点击。相反,你需要检查目标图层是否处于激活状态。如果没有激活,可能需要执行撤销操作。(其他需要检查的事项包括刚才提到的锁定按钮,以及你是否在尝试对当前选区之外的区域进行操作。选区可能处于不可见状态,你可以使用Ctrl+T来切换其可见性。) 关于图层的更多内容,请参考手册。 GIMP中的选择、复制和粘贴功能 当然,有一些真正的艺术家能够从零开始创作图像,但我认为我们大多数人在GIMP中进行创作时,还是会从其他地方获取素材作为起点。 几乎所有类型的位图图像都可以直接在GIMP中打开。GIMP会将其声明为“已导入”——因为GIMP的原生文件格式是XCF格式——但它可以导出回原格式,或导出为几乎任何其他类型的位图文件。粘贴
另一种导入素材的方式当然是,从其他应用程序或GIMP中打开的另一张图像复制内容后,将其粘贴到GIMP中。 在GIMP中进行常规粘贴(Ctrl+V)时,粘贴的内容会创建一个名为浮动选区的临时图层。你可以移动该图层并对其进行操作,但在执行以下两个操作之一前,无法切换到其他图层:要么将其创建为新的永久图层,要么将其锚定(Ctrl+H),即将其与之前的活动图层合并。 显然,在粘贴并锚定内容之前,你应确保已激活正确的图层。或者,你可以将粘贴的图层设为一个新的独立图层(如果你为其命名,这将自动完成),并在之后的某个时候将其与下方的图层合并。如果你希望粘贴的内容在GIMP中成为一个新图像并显示在单独的窗口中,请使用Shift+Ctrl+V快捷键。
“粘贴到”功能的工作方式与普通粘贴类似,但如果已锚定,粘贴的图像将根据当前的任何选区进行裁剪。默认设置是取消当前的任何选区。 复制 GIMP中的默认复制方式是仅从活动图层复制。“复制可见内容”(Shift+Ctrl+C)则复制合并后的图像(会考虑图层的当前可见性设置)。 GIMP中的选区 为了限制图像中被复制的部分——例如,如果你只想复制怪物的图像,而不包含原始图像中的任何背景——可以创建选区。选区也有助于限制要编辑或删除的内容等。只要存在选区,编辑工具通常就无法对选区之外的内容进行操作。这里有大量不同的选择工具,但它们有一个共同点,那就是都可以在四种模式中的一种下运行:替换、添加、减去和交叉。默认模式是替换模式。其他模式可以在开始使用鼠标(按下鼠标左键)之前通过按住Shift键和/或Ctrl键来选择。鼠标光标旁边会出现一个小符号,确认将要执行的操作类型。
模式 按键 符号 上一选区 替换 已移除 添加 Shift + 添加到 减去 Ctrl − 从…减去 交叉 Shift+Ctrl ∩ 与…交叉 除了使用Shift和/或Ctrl键外,每个选择工具在其工具选项中都有模式按钮。 请注意,在开始进行选区操作(按下鼠标左键)后再按下Shift和/或Ctrl键,会产生其他效果,具体效果因选择工具而异。 有关不同选择工具的工作方式详情,请参阅其文档。这些工具都各有用途(智能剪刀工具可能除外,连GIMP手册似乎都不推荐使用)。
我来介绍一下模糊选择工具(魔棒工具)的一项功能——该功能同样适用于按颜色选择工具。这些工具都设有阈值设置,用于决定颜色与你点击处颜色的偏差程度,偏差在阈值范围内的颜色会被纳入选择范围。若阈值为零,则只有与你点击像素颜色完全相同的像素才会被选中。 阈值可以在工具选项对话框中进行调整,不过还有一种更便捷的调整方式:在你点击选定参考像素后,向下或向右拖动鼠标即可提高阈值。如果选择范围超出了预期,只需稍微回拉(将光标向上或向左移动)。当选择范围合适时,松开鼠标左键即可。(提示来自Franknfurter)你可以将阈值设置为任意起始值,然后通过鼠标向上/向左或向下/向右移动来调整。不过我个人将这两个工具的默认阈值都设为了零。工具选项可以通过编辑→首选项→工具选项→立即保存工具选项来保存。 快速蒙版:通过使用各种选择工具添加或减去选区,你可以逐步细化选区。不过另一种处理选区的方法是进入快速蒙版模式。点击图像窗口左下角的小方块(或按Shift+Q)即可进入该模式。
在正常模式下,选区会以动画虚线(即所谓的“行进的蚂蚁线”)显示。而在快速蒙版模式下,选区不会被覆盖,未选中的图像区域则会被红色蒙版覆盖。(右键点击小方块可配置此行为。) 快速蒙版的一个作用是能让你看清包含部分选区的真实状态(即那些既非完全选中也非完全未选中的像素)。这些区域会被红色蒙版部分覆盖,但覆盖程度不及完全未选中的区域。(“行进的蚂蚁线”仅显示选中程度超过一半的像素与不足一半的像素之间的分界线。)在快速蒙版模式下,任何绘画工具(工具列表末尾的那些,从油漆桶填充工具开始,到减淡/加深工具结束)都将作用于选区蒙版而非图像本身。用白色绘制的区域会成为选区的一部分,用黑色绘制的区域会从选区中移除,而用灰色绘制则会产生介于两者之间的效果。通常,你可能会选择使用铅笔工具或画笔工具(取决于你是否需要像素级的清晰度),但任何绘画工具都可以使用,例如混合工具可用于创建从白色到黑色的渐变效果。
点击前景色/背景色指示器左下角的小方块可重置这些颜色,确保使用的是纯黑和纯白。点击双向箭头可切换颜色。 再次点击左下角的小方块或按下Shift+Q即可退出快速蒙版模式,此时会重新显示选区边框。 更多实用的选择选项,请查看“选择”菜单。 像素锐度 许多工具都具备使图像效果平滑且无像素锯齿的功能。不过,在处理像本游戏精灵图这类小型图标类图像时,这可能并非你想要的效果——尤其是当你尝试创建单一精确颜色的区域时,比如游戏在没有 alpha 通道的图像中用于透明和阴影的颜色(分别为 RGB 0,0,0 和 255,0,255)。
前面提到的大多数选择工具都有抗锯齿选项,并且都具备羽化功能。如果你想要像素级的清晰度,应当确保这两个选项都处于未勾选状态。 至少就我观察而言,选择菜单中的“锐化”选项并非只是相对地锐化选区。它能立即让选区达到完全的像素级清晰——选区蒙版中只有黑白两色,完全没有灰色调。
在绘画工具中,铅笔实际上是画笔的像素锐利版本。它只会生成与设定的前景色完全匹配的像素,不会产生其他色调。而使用画笔时,边缘总会有一些柔化效果。 关于GIMP的几点补充说明: 256×64像素的TGA图像文件通常不需要达到50千字节那么大,除非它包含Alpha通道。 如果你的图像在任何地方都不是真正透明的,确保它不会保存Alpha通道(以免浪费空间)的一个方法是使用【合并图像】选项。这将产生两个效果,一是将所有图层合并为单个图层,二是移除任何Alpha通道(将透明部分替换为当前背景色)。
当然,在执行此操作前,你可能需要将项目保存为XCF文件,并保持所有图层完整,以防日后需要进一步编辑。虽然在退出前应该可以撤销合并操作,但还是建议这样做。 在图像→模式下,你可以确保自己确实在处理RGB图像。如果你从某些外部来源导入图像,它偶尔可能是索引图像,这种情况下你应将其转换为RGB。索引图像(包括任何采用旧GIF格式的图像)可能比RGB图像体积更小,但有两点需要注意:1.部分GIMP操作仅在RGB模式下能正常工作;2.游戏无论如何都要求使用RGB图像。 画布大小选项可用于在不缩放内容的情况下更改图像尺寸。关于GIMP的更多内容 在这个简要概述中,我尚未提及路径工具,使用该工具可以进行“模拟徒手绘画”等操作。如果你的鼠标操作不够稳定,可以为想要绘制的曲线和形状创建路径。你可以通过各种方式使用锚点微调该路径,然后对其进行描边。路径也可以作为另一种创建选区的方式。 我也没有提到图层蒙版——它类似于图层的(额外)阿尔法通道,但更容易单独编辑和操作——也没有提及各种颜色工具、变换工具和滤镜。不过我就先介绍到这里。 了解GIMP更多使用方法的首要来源当然是其官方手册。你应该已经通过程序获得了它,可从帮助菜单中找到,同时也可在网上获取。 一些教程也能在GIMP官方网站上找到。更多资源方面,有三个包含GIMP论坛和教程链接的地方,分别是GIMP Chat、GIMP Forums和GIMP Users。 《征服伊洛希姆4》中的透明度与阴影 游戏自带的精灵(位于Illwinter trs文件中)没有任何alpha通道。相反,游戏中要完全透明的像素在精灵图像中显示为黑色,而游戏中的阴影(半透明黑色区域)在精灵图像中则显示为亮品红色(绿色值为零,红色和蓝色值达到最大)。对于任何以TGA文件形式提供的图像,无论是精灵图还是模组横幅,同样的方法都适用。前提是你的图像没有alpha通道!如果有alpha通道,游戏会将所有透明度信息都存储在该通道中,不会在其他地方——任何亮洋红色在游戏中都会被直接视为亮洋红色。 因此,如果你采用这种方式,需要从精灵图中移除所有alpha通道。如前所述,你可以在GIMP中使用“拼合图像”选项来完成。(拼合图像前,使用前景/背景颜色控制确保背景颜色为黑色。)这样可以节省一些文件空间。
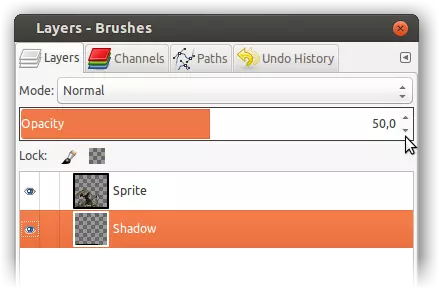
另一方面,如果你已经有一个背景完全透明的精灵图像(在选择并删除任何先前的背景之后),那么直接绘制带有 alpha 通道的阴影可能会更方便——这样你可以立即看到效果。 一种方法是: ❶ 首先在精灵图层下方添加一个单独的透明阴影图层。 ❷ 然后在该图层中将阴影绘制为纯黑色(在下方的单独图层中绘制时,无需担心会覆盖精灵图像)。 ❸ 最后,将阴影图层的整体不透明度降低至 50%。 深入了解纯文本文件 再次说明,c4m 文件只是一个纯文本文件,基本上可以用任何文本编辑器创建。如果你使用的是 Linux 系统,这应该就是你需要知道的全部内容。在Mac系统,尤其是Windows系统中,纯文本的概念可能需要一些解释——至少当你想在模组的描述或名称(即ASCII双引号之间的字符串)中包含任何非ASCII字符时是如此。 什么是纯文本文件?——UTF-8,现代的ASCII 曾经,纯文本等同于ASCII,即只包含128个ASCII字符的文件,其中包括用于换行和其他功能的控制字符。如今,每个此类字符(或其数字代码)都存储在8位字节中,且最高位始终为0。这基本上仍是你在任何普通程序源代码(以及编写c4m文件中的命令时)会用到的全部内容。不过,对于《极乐空间征服4》模组中的描述文本甚至名称这类普通文本而言,ASCII字符集有时可能显得有些不足。由于每个字节的最高位原本并未被使用,人们首先想到的自然是将这一位设为1,这样每个字节就突然多出了128个可用字符。因此,每个字符仍然只需一个字节。但遗憾的是,人们采用了多种不同的方式来实现这一点(当然,仅128个额外字符永远无法满足全球的需求),这就造成了诸多混乱。于是,在一段时间内出现了多种不同的代码页,而要让读者正确查看作者所写的内容,双方必须使用相同的代码页。代码页是黑暗时代的产物,那时还没有光明……没有Unicode……也没有UTF-8。说到UTF-8,它和前面提到的8位扩展(代码页)一样,只要文件或字符流中只使用ASCII字符,它就与ASCII完全相同。UTF-8文件或流中每个看起来像ASCII的字节(高位为0),实际上就是ASCII。因此,换行符、空格以及程序代码(或英文)在UTF-8中与以往完全相同。和之前的代码页一样,UTF-8中对ASCII的扩展仅通过高位为1的字节来实现。这意味着许多只支持ASCII的软件也能正确处理UTF-8。 不同之处在于,在UTF-8中,对ASCII的扩展被编码为多字节序列——长度为2、3或4个字节。这意味着任何 Unicode 字符(可能超过一百万个)都可以被编码。忘掉代码页吧。在 21 世纪,唯一值得关注的字符编码就是 UTF-8。 因此,简而言之,纯文本 = UTF-8。不用说,这对《神域征服4》也同样适用。 Windows 和 Mac 上的 UTF-8 遗憾的是,UTF-8 在 Windows 和 Mac 上的普及程度仍不及在 Linux 上,在这些系统上使用它需要用户做出一些特意的选择。这背后有历史原因,但我会将这个问题的背景留到最后一章再讲。 当然,如果你在描述和名称中只打算使用 ASCII 字符,这对你来说可能无关紧要。否则,请继续阅读。在Mac上 虽然我并非Mac专家,但我会简要说明一下我了解到的关于OS X系统中UTF-8编码的情况。据我所知,它不像Windows系统那样糟糕。 首先,默认的文本编辑器——如果我没记错的话叫做文本编辑,听说它表现不错。特别是,我认为它不会在你的UTF-8编码文件前添加任何无意义的BOM。不过,你可能需要关闭它的一些高级选项,并且在偏好设置→打开与存储→纯文本文件编码中,将打开和存储两个选项都设置为UTF-8。 将UTF-8设为环境默认编码 显然,在OS X系统中甚至可以将UTF-8设置为整个环境的默认字符编码。(若没有这个,UTF-8文件中的任何非ASCII字符在QuickLook中可能显示异常。)你的主目录下似乎有一个隐藏的小型文本文件~/.CFUserTextEncoding,其中包含一个由冒号分隔的两个数字的文本字符串。冒号后的数字是你的语言设置(0表示英语),而第一个数字是字符编码。将第一个数字更改为“0x08000100”(“0x”前缀表示十六进制)后,你的默认字符编码应设为UTF-8。 遗憾的是,问题在于Adobe软件(尤其是Illustrator)中存在的持续漏洞,在进行此更改后,这些软件可能会出现运行异常。如果你的电脑上安装了Adobe软件,那么你可能需要避免这样做(直到Adobe最终采取行动并修复此问题)。 在Windows系统上: 遗憾的是,在Windows系统中,将UTF-8设为整个环境的默认字符编码仍然完全不可行。据我所知,即使在今天,系统主要使用的仍然是传统代码页——控制台使用的是不同的(“DOS”)代码页,与其他地方的不同。(Windows上确实定义了编号为65001的UTF-8“代码页”,但其可用性非常有限。) 此外,我认为内置的记事本以及其他任何微软软件在保存UTF-8编码的文件时,都会坚持在文件开头添加一个BOM(字节顺序标记),而且无法关闭这种行为。BOM是一个不可见的Unicode字符,其真正的原始用途是帮助读取Unicode的软件确定多字节代码单元的字节顺序(即“字节序”)。(字节顺序可以从BOM代码U+FEFF的哪些部分在前、哪些部分在后看出。)还存在其他Unicode编码,如UTF-16和UTF-32,它们基于此类多字节单元(这也是导致它们在数据交换中显得不便的原因之一),但UTF-8并非如此。UTF-8中不存在字节顺序,因为每个代码单元都只是一个字节。尽管如此,为UTF-8添加BOM的一个常见理由——据称是需要给它一个“签名”——也没什么意义,真正的原因无疑可以在Unicode的历史中找到,详见章节末尾。因此,你最好使用其他工具来处理UTF-8编码文件。我认为,Windows系统下最受欢迎的记事本替代工具是免费开源的Notepad++。除了能很好地处理UTF-8编码外,它显然也能正常读取Unix换行符。可能也有更轻量级的替代工具能满足需求。但如果你选择使用Notepad++,以下是相关概述: Notepad++ 首先,在Notepad++窗口底部有一个状态栏,在那里可以即时查看当前编辑文件的字符编码和换行格式。

编码可在编码菜单中更改。该菜单分为两个部分,上方是“编码为”选项,下方提供“转换为”选项。对于新建的空白文件,这两部分内容相同。你需要选择的选项是“编码为UTF-8(无BOM)”。
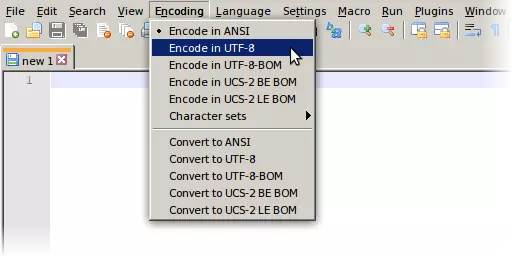
当文件中包含实际数据时,上下两组选项有所区别:上方的选项用于调整记事本++对现有数据的解读方式,而不会更改这些数据;下方的选项则会对数据进行实际转换(当然,只有当记事本++正确理解原始数据时,转换才能正常进行)。 如果您加载了之前的文件,且某些字符显示不正常,可以尝试使用上方的选项,直到(希望)字符显示正常。当然,这主要是为了找到特定的传统编码(代码页):在字符集下可以找到很多这类编码,而“ANSI”选项指的是其中在你系统中被设为默认的那一个。只有当所有内容看起来都正确时,你才应该使用下方的(转换)选项。
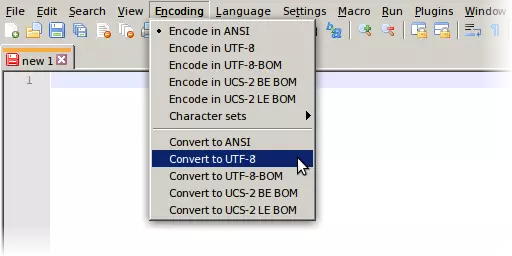
你也可以通过“编辑”菜单中的“行尾转换”功能,将换行格式更改为Unix格式——这是《神域征服3》手册所推荐的。不过我认为这并非绝对必要。(在我看来,《神域征服3》和《神域征服4》都能很好地处理Windows换行格式。)另一方面,这样做也几乎没有坏处,因为据我所知,唯一无法读取Unix换行格式的Windows软件恰恰是记事本。
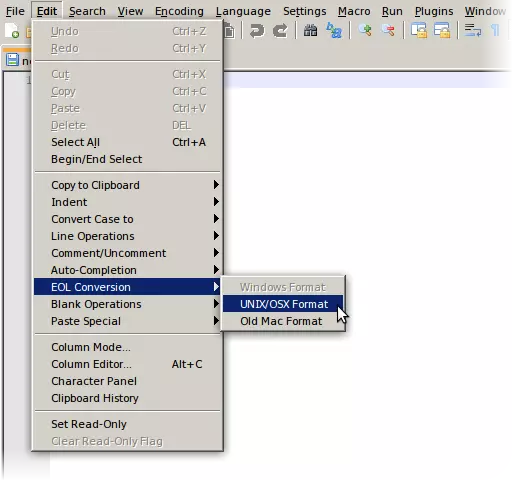
首选项 您无需在每次开始编辑时都进行这些调整,而是可以将其设为记事本++的默认设置。操作方法:打开设置菜单,选择首选项...
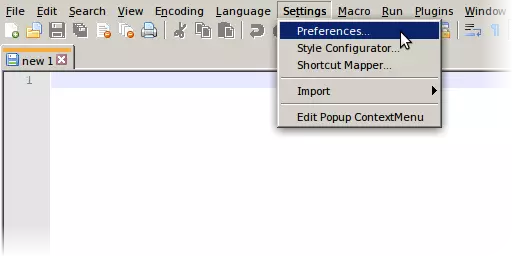
在打开的框的左侧,选择【新建文档】。
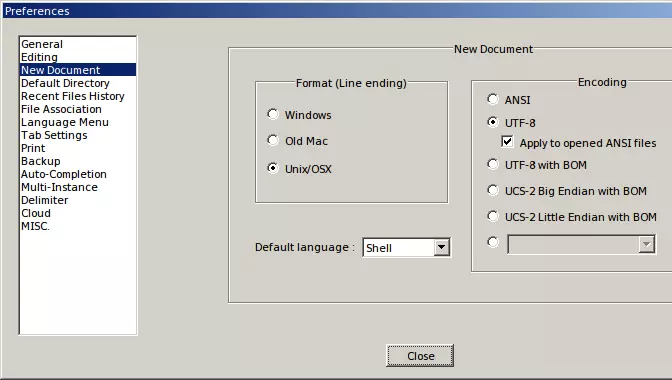
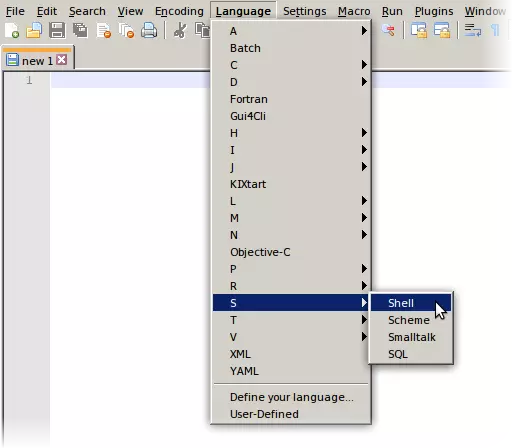
关于编码,我认为UTF-8应该已经被预先选中,并且相关的复选框处于勾选状态,但如果没有,请确保将其设置为UTF-8。 复选框的说明“Apply to opened ANSI files”(应用于已打开的ANSI文件)存在一定误导性。其实际作用是让Notepad++将你打开的任何ASCII文件(而非“ANSI”文件)视为UTF-8编码,即仅包含ASCII字符的文件。在Windows系统中,默认情况下会将ASCII文件视为采用系统默认的某种遗留代码页进行编码,这种代码页被不准确地称为“ANSI”。当然,只要ASCII文件仅包含ASCII字符,将其视为UTF-8还是“ANSI”编码都没有区别,因为这两种编码与ASCII完全兼容。不同之处在于添加到文本中的非ASCII字符的处理方式。这些字符应该以UTF-8编码,还是以您特定系统上默认设置的任何旧版代码页编码? 即使勾选了该框,如果加载了非ASCII、非UTF-8的文件,Notepad++仍应将其识别为“ANSI”(当然,除非它是某种UTF-16或UCS-2)。一个奇怪的现象是,加载完全空的文件(零字节内容)时,出于某种奇怪的原因(不确定为什么),它也可能被视为“ANSI”,在这种情况下,您可能需要从编码菜单中明确选择UTF-8。 如果您愿意,默认的换行符(行结束符)也可以更改为Unix格式,不过,同样,我认为这不太重要。语言 默认语言选项主要与美观有关。它指的是为文本假定的编程语言,当然你也可以将其保留为普通文本。在上面的示例中,我将其设置为Shell,这会使Notepad++将文本着色,就好像它是一个Unix shell脚本一样。《极乐空间征服4》的模组当然不是Unix shell脚本,但以“#”字符开头的注释工作方式相同,Notepad++会将这些注释显示为绿色。(“编辑”菜单中的“注释/取消注释”选项也将起作用。)字符串字面量(在ASCII双引号之间)也会以与命令不同的方式显示。 你也可以从菜单中选择语言选项:
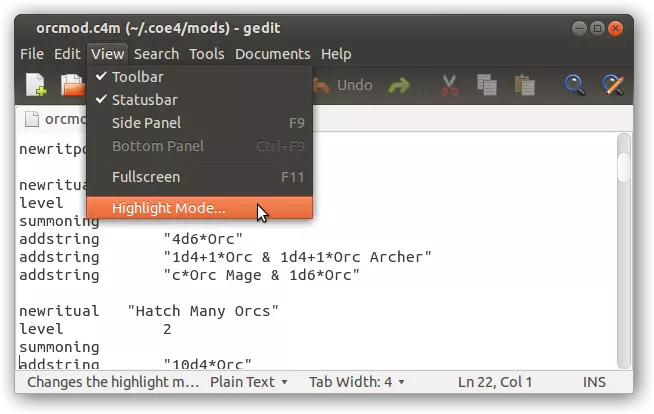
在Linux系统上,在Linux创建的纯文本文件显然始终是UTF-8编码且不带BOM(有一个讨厌的例外情况:如果你从LibreOffice保存纯文本,文件会带有BOM)。无论出于何种原因,如果你不幸发现自己的UTF-8文件被BOM污染,删除它应该不会太困难。像Gedit或Nano这样的简单文本编辑器会将其视为文本开头一个不可见的零宽度字符。因此,当你移动光标时,如果注意到那里有一些不可见的垃圾字符,只需确保光标位于文本开头,按一次删除键,然后保存,BOM垃圾就会被清除。更高级的编辑器,如Vim或Geany。org](也适用于Windows和Mac),有处理BOM移除的特殊选项。 彩色编辑 Gedit用户可在“视图”菜单中找到语法高亮显示功能。
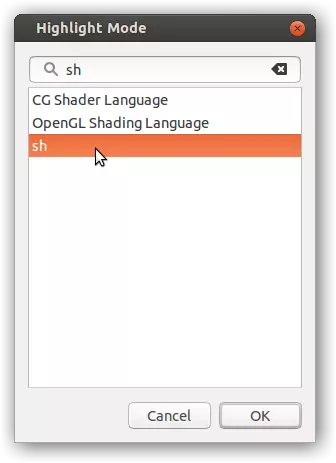
如果你在搜索栏中输入“sh”来缩短编程语言列表,然后选择sh选项,Gedit会将你的模组显示为Shell脚本。这样一来,注释和字符串字面量就会变得易于识别。 有一个小奇怪的地方是,模组中任何出现的free命令都会与其他命令区分开来。这是因为free是一个实际的Linux命令(尽管不是通用Unix中的命令)。其他【Conquest of Elysium 4】命令则不是,它们只会以标准的黑色文本显示。不过,这种文本显示上的小不一致几乎不会造成任何影响。 输入Unicode字符 假设你已经正确设置了UTF-8(参见前面的章节),现在你可以在描述和名称中尽情使用非ASCII字符了。部分字符可通过键盘设置直接输入(例如带重音符号的按键),但许多Unicode字符并不容易直接访问。 复制粘贴是一种无论应用程序和操作系统如何都能奏效的解决方法:从其他地方(如网页、文字处理器或大多数操作系统都有的字符映射工具)复制所需字符,然后粘贴到纯文本编辑器中。 选中应用程序中的内容后按Ctrl+C复制,切换到另一个应用程序后按Ctrl+V粘贴,这是在任何地方都能通用的操作命令。FreeSans字体有一些额外的字符,比如比Latin-1补充字符集中更多的普通分数和上标数字(还有下标数字),而Liberation Serif字体在这方面的字符则少一些。 查看字体文件内容的一种方法是使用FontForge加载它们——这实际上是一个功能齐全的字体编辑器,而不仅仅是查看器,但它能正常工作。 语言支持 Unicode字符集中的大部分字符是用于东亚文字的表意文字,但我认为游戏的字体中并不包含这些字符。(当然,如果包含的话,字体文件会比现在大得多。)这些字体中似乎也没有阿拉伯语,而且文本系统似乎无论如何都无法处理从右到左的书写方式。不过,如果你只想使用英语以外的其他欧洲语言(希腊语和西里尔字母也受支持,但不包括在花哨的字体中),或者只是想用一些变音拉丁字母来装饰你的名字,这些字体中的内容可能已经足够了。(不过在Mac上,使用Command键(⌘)来代替Ctrl键。) 通过十六进制代码直接插入Unicode字符 在大多数系统上,也有通过十六进制代码直接输入Unicode字符的方法(Unicode字符通常就是这样记录的)。例如,U+263A代表☺(其中“263A”是实际代码)。 在Windows系统上,如果该功能可用,操作步骤如下:①按住Alt键,②按小键盘上的+键,③输入代码,④松开Alt键。 遗憾的是,由于某些奇怪的原因,此功能并非默认启用,甚至通常都未启用(在我的Windows 8.1系统上就未启用),启用它需要进入注册表设置进行操作。注册表项HKEY_CURRENT_USER Control Panel Input Method应包含一个类型为REG_SZ(字符串)的EnableHexNumpad值,且该值需设为“1”。此处修改后,需注销并重新登录才能生效。(对于非常旧的Windows系统,如XP,则需要重启。) 或许我还应该提及一个简单的工具,它提供了另一种Unicode输入方法(有点类似于下面提到的Linux上的GTK+方法)。我对此不承担任何责任。它不是开源的,根据作者(似乎名为Andrew Marcuse)的说法,表面原因是它非常简单,他认为不值得费心去发布源代码。但它是免费的,而且就我所知,它似乎能完成它应有的功能,没有其他多余功能。 在Mac上,我建议你参考苹果支持论坛上提供的解决方案。 在Linux系统上,如果你的图形环境是基于GTK+的(这意味着大多数Linux系统,但不包括那些基于Qt的KDE系统),那么它应该可以直接使用: ❶ 按下Shift+Ctrl+U(然后松开),会显示一个带下划线的u; ❷ 输入代码(输入时代码会显示出来并且可以编辑); ❸ 按Return或Enter键(或按空格键,或再次按下并松开Shift+Ctrl)完成输入。 如果这不起作用(你没有看到任何u),那么可以尝试在按住Shift+Ctrl的同时输入U和代码,然后再松开Shift+Ctrl。在Linux系统的KDE桌面环境下,遗憾的是目前没有通用的解决办法。不过,在KDE默认的文本编辑器Kate中,或许可以采用特定于应用程序的方法:按F7调出命令行,然后输入“char 0x263A”(或其他所需Unicode字符的代码)。 关于这一点,可进一步查阅维基百科了解相关内容。 字体(及文本系统) 恐怕现在需要给大家的热情降降温了。虽然从理论上讲,借助UTF-8编码,整个Unicode字符集都可供使用——目前已分配的字符超过12万个,而可用的代码点多达1112064个——但实际上存在一个小问题:字体。当应用程序使用系统字体时,如果其首选字体中缺少某个Unicode码位的图形表示(字形),操作系统可能会从已安装的其他字体中提供替代字体。 然而,像《神域征服4》这样的游戏无法合理依赖任何特定于操作系统的字体系统。它必须提供自己的字体,而《神域征服4》正是这样做的。 在游戏的数据文件夹中,有三个TrueType字体文件:guifont.ttf,我认为它是来自GNU FreeFont系列的FreeSans。这是一种无衬线字体,拥有最大的字形集,即支持的字符数量最多,游戏中的大多数内容都使用该字体,包括模组描述、职业描述、仪式描述和消息文本。guifont_texty.ttf,似乎采用了【Liberation Serif】字体,但其字符集规模略小。该字体用于单位描述文本。 guifont_fancy.ttf,显然采用了由Dieter Steffmann设计的【Cloister Black Light】字体。它的字符集规模最小,用于各类标题文本,包括单位属性面板中显示(名称及)单位类型的标题。 符号与数学相关内容 近年来,许多新的表情符号及其他趣味符号被纳入Unicode标准,但这些最新添加的符号未包含在游戏字体中也不足为奇。(为了能在各类网站上正常显示其中部分符号,我最近发现即便是预装的系统字体也不够用,不得不额外安装更多字体。)更令人失望的是,游戏中的所有字体,甚至FreeSans,都几乎不包含【Dingbats】和【Miscellaneous Symbols】字符块中的内容,尽管这些字符块已被纳入标准相当长一段时间(除了少数最近新增的部分)。 GNU FreeFont系列中的另一种字体FreeSerif,确实包含上述两个字符块中大部分内容的字形。当我尝试用它替换游戏的guifont.ttf时,像❶❷❸❹、⚔、☠、⚕、✌、☄、⚓、⚒、⚠、⚑、⚐、➳、☛、✔、✘、⚅、♒、☼、☀、☁、⚡、❄、☃、♨、☤、⚚这样的符号在游戏中都能正常显示。DejaVu字体项目中的DejaVuSans也是如此。显然,由于游戏并未附带FreeSerif和DejaVuSans字体,所以不能指望《征服伊洛希姆4》的玩家普遍能正常显示这些字符,它们并不包含在游戏自带的字体中。 在游戏字体(除了花体字体外)中可以找到的字符包括:☺ ♠ ♣ ♥ ♦ ♪ ♫、序号符号(№)以及箭头区块中的一些箭头,如←↑→↓↔↕。当然,除了ASCII字符集外,所有字体(包括花体字体)都包含完整的Latin-1补充字符集。所有字体中还包含一些其他符号,如† ‡ • ‰ ∞ ≈ ≠ ≤ ≥。

示例《极乐空间征服4》地图中的名称包含一些非ASCII字符。(《极乐空间征服4》的地图文件即coem文件,和模组一样,都是UTF-8文本文件。) SDL_ttf库 事实证明,除了字体外,还有一个问题。 上述提到的DejaVuSans字体除了对Dingbats和Miscellaneous Symbols有良好支持外,还包含一些从U+1F600开始的表情符号等。但即使将该字体替换为游戏自带的字体,这些表情符号在游戏中仍然无法显示。使用George Douros的Aegyptus字体进行的实验同样无法显示古埃及象形文字。 其原因完全在于游戏用于文本显示的SDL_ttf库。尽管 Unicode 字符需要 32 位变量来存储(准确地说是 21 位),但在该库中,由于某些原因,它们到处都被缩减为仅 16 位。(例外情况是,UTF-8 字符串中的字符会被正确读取为 32 位值——但这并没有太大帮助,因为之后它们还是会被缩减为 16 位。)这意味着,只要只使用前 63000 个左右的 Unicode 字符,一切都能正常工作,但任何超出此范围、在超过一百万可能的字符中无法容纳在 16 位内的 Unicode 字符都会被损坏。然而,由于当时其多个成员(包括微软、苹果和 Sun)已在固定宽度 16 位字符编码模型的软件上投入巨资,为了挽回颜面和保护投资,UTF-16 方案也被拼凑出来——它试图模仿 UTF-8 的自同步特性,却毫无后者的优雅。在 Unicode 2.0 的表述中,新的 UTF-16 方案最初被指定为主要编码,而 UTF-8 只是次要选项。(此后情况发生了变化,Unicode 联盟不再推荐任何一种编码优于另一种。)尽管UTF-16的编码宽度不如UTF-8那样可变,但其支持者仍将其吹捧为“几乎”固定宽度,理由是“几乎不需要”第二个16位代码单元(当然,从编程角度来看这完全是无稽之谈,因为双单元情况仍然需要处理)。 UTF-8方案可以对ISO/IEC最初设想的整个31位UCS内的任何内容进行编码(超过二十亿个码点),而UTF-16方案最多只能编码略超过一百万的码点,准确地说是1112064个可用码点。(其中2048个码点被移除,仅为UTF-16方案保留,同时在Unicode最初目标的基础上又增加了16个65536字符的“平面”。)ISO/IEC最终(在2000年)同意将ISO/IEC 10646的代码空间限制为不超过UTF-16可编码的范围(将UCS从31位缩减为未完全使用的21位集合),从而使这两个标准的统一达到100%完成。如今,Unicode和UCS基本上是同一事物(尽管Unicode无疑比UCS或ISO/IEC 10646听起来更吸引人)。 UTF-8通向Unicode之路 由于在GNU/Linux世界中,从未实现过对16位字符编码的内部支持,因此选择UTF-8用于所有事物变得顺理成章。直到2002年,红帽成为首个迁移到UTF-8的Linux发行版,随后SUSE于2004年、Ubuntu于2005年、Debian于2007年跟进。总而言之,Linux向Unicode的完整迁移过程相当迅速且顺利。当然,与此同时,万维网也基本都采用了Unicode,同样是通过UTF-8(UTF-16几乎从未被视为替代方案)。在这两种情况下,摒弃UTF-16最重要的原因无疑是它与现有的ASCII软件和文本文件不兼容,而且在传输方面,UTF-8比UTF-16具有更强的稳健性。(此外,通常情况下UTF-8的文件大小也比UTF-16更小。)微软和苹果(以及联盟中的其他公司)显然对此并不满意。在20世纪90年代初,他们曾大胆且勇敢地迎接未来,推出了一系列软件来处理全新的固定宽度字符集UCS-2,无疑付出了相当大的成本。然而,随着Unicode 2的出现,他们不得不痛苦地将固定宽度的UCS-2系统调整为可变宽度的UTF-16——这种调整至今仍未在所有地方完成。(这使得他们的系统中充斥着遗留代码页、UCS-2、UTF-16,当然还有不可避免且日益普及的UTF-8。)如今,更雪上加霜的是,他们只能眼睁睁看着其他人干净利落地(相对而言)毫不费力地选择了更为简便的100% UTF-8这条通往Unicode的道路。不过,似乎没有哪家公司像微软这样,在适应UTF-8的成功方面经历了如此艰难的过程。(相比之下,Sun公司(现归Oracle所有)的Java平台在内部也使用UTF-16——这是其创建于20世纪90年代初的结果——但他们从很久以前就开始建议在外部使用UTF-8。)鉴于UTF-16LE在微软软件中仍被持续且误导性地简称为【Unicode】(内容无法识别或无法翻译,已删除)关于UTF-8“签名”的误区 这让我想到一个流传甚广的误区:UTF-8需要某种额外的“签名”,即在真正的UTF-8流前添加前缀,才能被识别为UTF-8。 当然,这个误区的根源在于,尽管UTF-8不存在字节顺序问题,但某些软件,尤其是Windows上的软件,却随意在UTF-8中加入字节顺序标记(BOM)——这种习惯无论如何都需要合理化。 事实如下:在UTF-16中,如果将随机字节流解释为某种UTF-16(BE或LE),每个字符被视为合法UTF-16的概率为96.9%。(这未考虑对当前未分配代码点的检测和/或任何文本内容的分析。)因此,需要相当数量的字符才能以合理的确定性排除非UTF-16的情况。 然而,UTF-16的字节顺序问题几乎要求其前面加上一个BOM(字节顺序标记),该标记为两个字节——在UTF-16BE中是0xFE、0xFF,在UTF-16LE中是0xFF、0xFE。由于BOM已经存在,它也将作为UTF-16的签名。 两个随机前导字节对应UTF-16LE BOM的概率为0.001526%,这使得识别UTF-16LE比读取350个随机UTF-16LE字符更可靠。 相比之下,在UTF-8中: 没有字节顺序。任何可合法解码的非ASCII字符的出现,都极有可能表明其编码方式为UTF-8。在随机字节流中,一个非ASCII字节(高位设置)开始的序列能够被合法解码为实际非ASCII字符的概率仅为6.64%。仅五个这样的字符就能更可靠地确认字节流为UTF-8(错误概率为0.000129%),其可靠性超过UTF-16LE的BOM。(这五个UTF-8非ASCII字符在格式识别上的可靠性,相当于UTF-16LE的BOM加上额外检查78或79个UTF-16字符是否存在非法UTF-16的可靠性。)另一方面,如果字节流是纯ASCII(每个字节的高位均未设置),那么编码方式的问题就已经确定了。实际上,我下载了该库的源代码并进行了修复(结果发现异常简单),之后我确实让《征服伊洛希姆4》能够显示那些表情符号和象形文字(使用正确的字体)。或许这个修复最终也能添加到官方的SDL_ttf库中(不过目前我还没有收到SDL方面的任何消息)。 ASCII字符的排版变体 ASCII字符集包含一些多用途字符: "(U+0022):ASCII双引号。既用作左引号也用作右引号,还可作为双撇符号(表示秒或英寸)。 '(U+0027):ASCII单引号或撇号。也可作为单撇符号(表示分或英尺)。 -(U+002D):ASCII连字符减号。用于连字符、减号、短横线(或长横线)。根据定义,ASCII 也是合法的 UTF-8。无论你称之为 UTF-8、ASCII,还是给它贴上一些任意的遗留代码页标签(所谓的“ANSI”或其他),都无关紧要。它们本质上都是 ASCII。只不过,如果将其视为 UTF-8,那么对它的任何非 ASCII 补充都将被合理编码。 UTF-8“签名”(以字节顺序标记的形式)在无字节顺序的 UTF-8 中会变成三个字节(0xEF、0xBB、0xBF),这使得格式检测出错的概率仅为 0.000006%。这相当于 UTF-16LE BOM 的可靠性,再加上对 176 个(!)以上的 UTF-16 字符进行非法 UTF-16 检查的可靠性。另一方面,普通UTF-8流中的仅七个非ASCII字符将比BOM“签名”更加可靠,错误概率不到其十分之一。 总结: 尽管与UTF-16不同,UTF-8本身确实非常容易识别,并且没有字节顺序需要标记,但字节顺序标记无论如何都会使其变得极其容易。太好了!哦,但是等等…… 如果这个可能是有史以来设计的最容易识别的字符编码(UTF-8本身)真的需要在其之上添加这种额外的签名——那么识别性较差的UTF-16难道不应该同样“改进”,添加大量额外的BOM作为签名吗? UTF-8 BOM破坏了UTF-8的一个优点:它与ASCII以及ASCII软件的100%兼容性。你是否认为为了将其辨识度提升到荒谬乃至更高的水平,这样的代价是值得的,这很可能取决于你最初对UTF-8的喜爱程度。(就微软而言,我认为可以有把握地假设这种喜爱程度为零。)作为一个干扰那些期望接收ASCII码却在使用UTF-8时本可正常运行的软件的因素,UTF-8“签名”的效果非常显著。(我本想在这里链接到《辛普森一家》中伯恩斯先生的相关内容,但似乎没有必要。)尽管UTF-8识别看似简单直接,但微软似乎从未费心在其软件中实现这一功能,这使得他们自己发明的UTF-8“签名”成为检测UTF-8的唯一方式。讽刺的是,微软软件无法以正常方式识别UTF-8的这种特殊缺陷,有时甚至可能是件好事。如果Windows系统上的开发者尝试使用UTF-8源文件——带有微软坚持要求的UTF-8 BOM——那么微软自家的开发工具显然会自行将该UTF-8文件转换为其他格式,从而损坏源文件中的任何UTF-8字符串文字。解决方法:无论如何,保存不带BOM的UTF-8源文件。org],使用非微软工具。如果没有黄色徽章将其标记为UTF-8,微软开发工具将无法识别(会将其视为“ANSI”),并保持其原样。 不过,再一次,从纯粹的人类角度来看,我想他们对UTF-8明显的强烈反感也不是那么难以理解。 注意事项 * 在这些最后章节中,我可能有些随意地交替使用了“字符”和“码点”这两个术语,这在编程讨论中也是常见做法。然而,就文本显示而言,从最终用户的角度来看,一个字符可能由两个或更多码点组成,其中一些码点例如可能是组合变音符号。另一方面,连字可以被视为两个或多个字符,即使由单个代码点表示。对于参与Unicode文本显示的开发人员而言,Unicode和ISO/IEC 10646之间仍然存在区别,因为Unicode标准为此类内容制定了各种ISO/IEC标准中没有的规则。当你在键盘上打字时,得到的主要是上述ASCII字符。不过,文字处理软件可以自动将其中一些字符替换为合适的排版变体。完整的Unicode字符集为每种特殊情况都定义了字符,通常能让文本看起来更好一些。对于ASCII双引号,由于其完全不能在字符串文本中使用,因此若需要使用引号,唯一的解决方法是使用其印刷体对应符号,因为这些符号不会干扰游戏对字符串文本起始和结束的识别: “(U+201C):左双引号 ”(U+201D):右双引号 ″(U+2033):双撇号(秒/英寸) ‘(U+2018):左单引号 ’(U+2019):右单引号或撇号 ′(U+2032):单撇号(分/英尺) ‐(U+2010):连字符 −(U+2212):减号 –(U+2013):短破折号 —(U+2014):长破折号 这些符号在所有游戏字体中均有收录,但减号、单撇号和双撇号不在花体字体中。在 Unicode 中,大多数标点符号位于【常规标点符号】区块。不过,减号(U+2212)位于【数学运算符】区块。 不间断空格和不间断连字符 另一个常用的字符是 U+00A0,即不间断空格:它看起来和普通空格一样,但会防止在该空格处发生换行。例如,如果你写“№ 2”,可能不希望在“№”和“2”之间换行,那么在这两个字符之间使用不间断空格就能确保不会出现这种情况。 还有一种不间断连字符 U+2011。不过,我认为《神域征服4》在普通连字符(或 ASCII 连字符减号)后也不会换行,所以在制作《神域征服4》模组时,这个字符的用处不大。再次提醒,任何供游戏读取而非玩家阅读的字符都应使用ASCII编码。 UCS、Unicode与UTF-8的历史——第一部分 这些结尾章节可以安全跳过。它们仅提供了Windows和Mac系统在采用UTF-8方面进展明显缓慢的一些历史背景。我原本将其写成了一个章节,但显然Steam不允许章节(或部分)过长,因此我不得不将其拆分为两部分。 开端 20世纪80年代,两个项目相继启动,最初彼此互不知晓,均旨在为全球创建一个统一的字符集。其中一个项目由ISO/IEC于1984年发起,1989年开始分发新标准ISO/IEC 10646的草案,并于1990年正式发布。另一种后来被称为Unicode的编码,始于1987年施乐和苹果公司的一个非正式项目,1989年随着定期会议的召开和更多公司的参与而发展(微软于1990年加入),并在1991年成立Unicode联盟后正式确立。 Unicode项目的最初目标——微软和苹果为此投入了大量资金和声誉——是一个固定宽度的16位字符集。也就是说,每个字符都固定占用16位单元(即2字节)。这意味着它与旧的ASCII文件、所有其他先前的编码以及所有先前的文本处理软件完全不兼容,并且即使对于英文文本和程序源文件,它也会占用两倍的空间。不过,从好的方面来说,由于仍然采用固定宽度(只是使用16位单元而非字节),新软件处理起来会像旧软件处理之前的单字节编码一样简单。 与此同时,ISO/IEC项目的理念——即通用字符集(UCS)——是一个完整的32位集合(更准确地说是31位集合),相比之下,Unicode是16位集合。而且与Unicode不同,ISO/IEC始终预见到会对其使用可变宽度编码。事实上,1992年精心设计的UTF-8方案不仅与ASCII兼容,还具有自同步性,并且(在存在非ASCII字符时)非常容易识别,它最初是为编码ISO/IEC 10646的整个31位UCS而设计的,而非Unicode。合并(及UTF-16) 这两个项目最终实现了合并,不过是分阶段进行的。首先,两个项目的字符集相互对齐,同时各自都未放弃其总体目标。这实际上使Unicode成为了基于ISO/IEC 10646标准的UCS的一个子集,即UCS-2,该子集仍仅以固定宽度的16位单元进行编码。直到此时,Unicode的相关人员才意识到,他们终究还是得在热切期望的固定宽度编码这一问题上认输。16位,也就是65536个字符(码点),根本不足以容纳他们认为必需的所有字符(当然,尤其是所有的汉字)。 在这个节点(1996年7月,Unicode 2.0版本),UTF-8被Unicode所采用。






