换一换
换一换 





各位工程师们,大家好!我们非常高兴地宣布,《戴森球计划》的开发工作在过去几个月里稳步推进。每一行代码和每一个新想法都凝聚了我们团队的辛勤付出与不懈努力。我们希望这些成果能为大家的游戏体验带来更多惊喜与提升!

(载具系统:已激活!) 坏消息:CPU 已达极限 在开发和持续维护过程中,我们逐渐意识到性能瓶颈问题。载具系统的实装将引入数千个启用物理效果的组件,而当前架构根本无法支撑。 早在蓝图系统出现之前,我们曾认为“每分钟 1000 个宇宙矩阵”的工厂会达到硬件极限。然而,你们的创造力打破了预期——对部分玩家而言,10000 个宇宙矩阵只是入门级挑战。尽管我们迅速推出了多线程系统并花费数年时间进行优化,但玩家们仍不断将自己的电脑推向极限,甚至有先驱者实现了每分钟 100000 乃至 1000000 个宇宙矩阵的产量!显然,是时候进行一次重大的性能提升了。在对现有代码结构进行全面审查后,我们发现多线程系统仍有巨大的优化潜力。因此,我们近期的工作重点是对《戴森球计划》的多线程框架进行彻底改造,为载具系统的未来发展奠定基础。
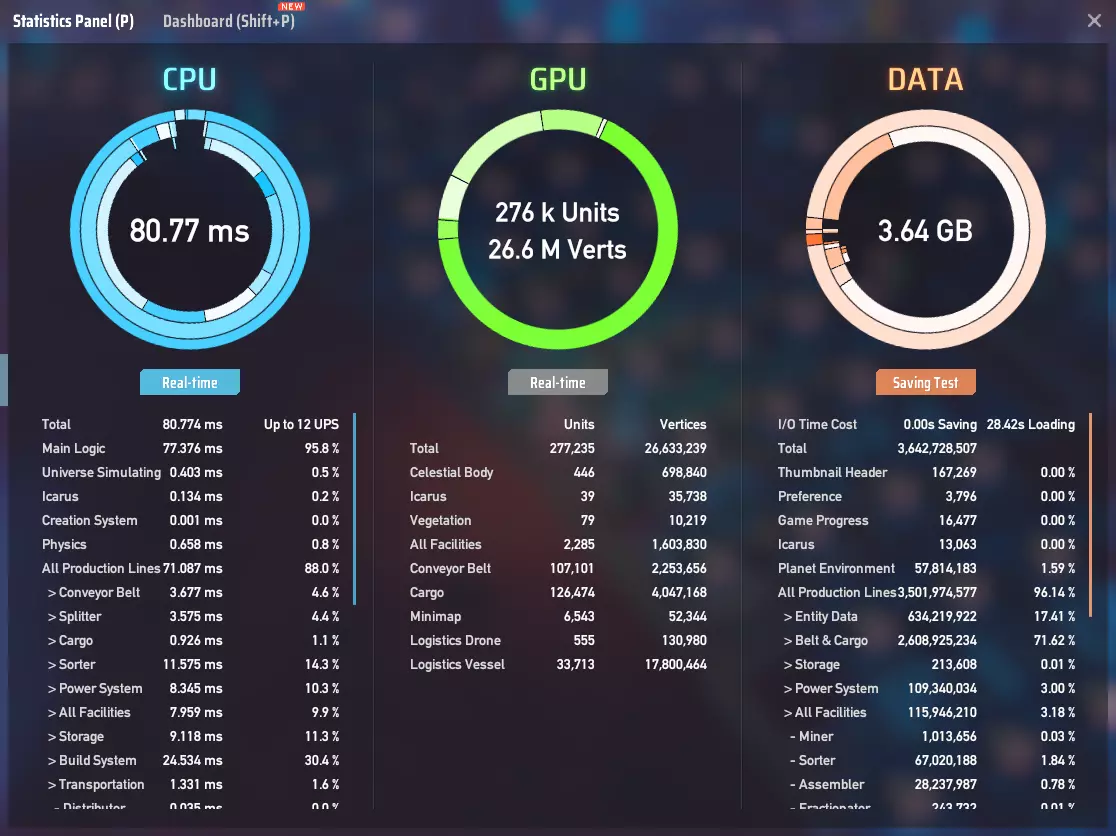
(来自100K矩阵存档的性能快照。整条生产线的逻辑帧时间达到80毫秒。) DSP中的多线程 让我们简要介绍一些多线程基础知识、DSP为何使用多线程以及我们为何要重建该系统。 以装配机的生产周期为例。忽略物流因素,其逻辑可分为三个阶段: 1. **电力需求计算**:装配机的电力需求会根据其是否缺少材料、是否被输出阻塞或是否处于生产中期而变化。 2. **电网负载分析**:电力系统会汇总发电机的所有供电能力,并将其与总消耗量进行比较,然后确定电网的供电比例。 3.生产进度:根据电网负载以及资源可用性、增殖剂涂层等因素,计算该帧的生产增量。 单独来看,这些计算微不足道——每个装配机可能只需几百到几千纳秒。但在游戏后期存档中,当装配机数量扩展到数万乃至数十万时,处理器可能会突然陷入按顺序处理这些计算的状态,耗时达到毫秒级,从而导致帧率骤降。
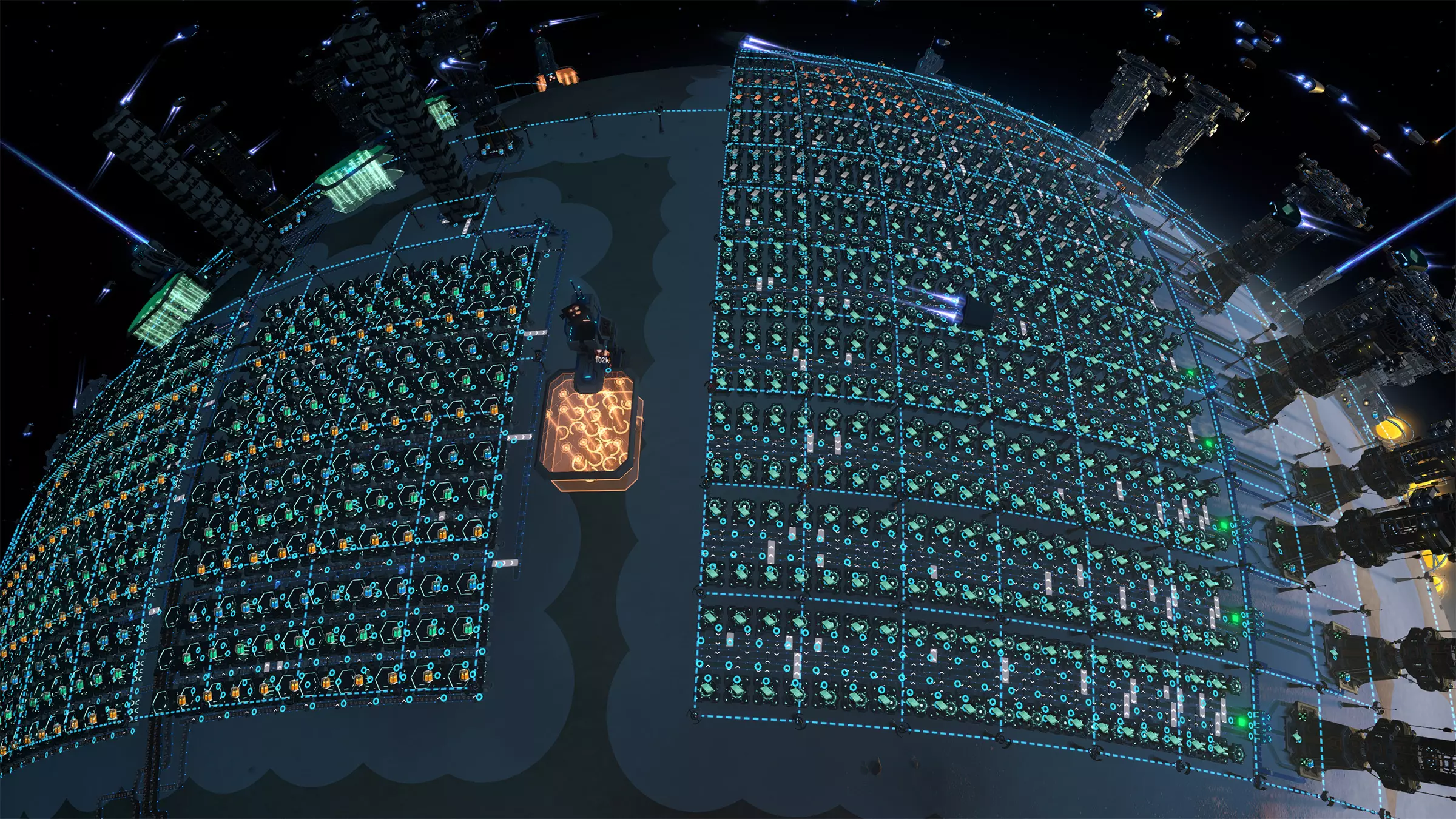
(这片由组装机构成的海洋,得益于不懈的优化,运行得十分流畅。) 幸运的是,大多数现代CPU都拥有多个核心,能够并行执行计算任务。如果你的CPU有8个核心,并且将工作负载平均分配,每个核心的负担就会减轻,从而减少整体所需时间。 但问题在于:并非每台组装机的处理时间都相同。核心性能的差异、后台任务以及操作系统的调度,意味着线程很少能同时完成——你总是在等待速度最慢的那个。因此,即使拥有8个核心,你也无法获得8倍的速度提升。 那么,下一站:巫师模式。

好了,玩笑归玩笑。我们来认真谈谈多线程面临的挑战。当多个CPU核心并行工作时,你不可避免地会遇到诸如内存限制、共享数据访问、伪共享以及上下文切换等问题。例如,当多个线程需要读取或修改同一数据时,必须引入通信机制以确保数据完整性。这种机制不仅会增加开销,还会迫使一个线程等待另一个线程完成。 此外,还需要处理时序依赖问题。让我们回到三阶段装配机的例子。在第二阶段(电网负载计算)运行之前,所有装配机都必须完成第一阶段(电力需求更新)——否则,电网可能会使用上一帧的过时数据。为解决此问题,《戴森球计划》的多线程系统将每帧游戏逻辑拆分为多个阶段,并分离出繁重的工作负载。随后,我们会识别出哪些阶段是顺序无关的。例如,当装配机计算当前帧自身的电力需求时,其结果并不依赖于其他建筑的电力需求。这意味着我们可以安全地在多个线程上并行运行这些计算。

旧系统存在的问题 坦率地说,我们的旧多线程系统已经显露出其局限性。它的执行效率顶多算平庸,而且其设计使得各种多线程任务的调度变得困难。每个多线程阶段都伴随着高昂的同步成本。随着游戏的不断发展和更复杂内容的加入,每帧的逻辑工作量稳步增加。将任何单个逻辑块转换为多线程处理往往只能带来微不足道的性能提升,同时却大大增加了代码维护的难度。 为了更好地了解逻辑的哪些部分占用了CPU时间,以及旧系统究竟在哪些方面存在不足,我们构建了一个自定义性能分析器。以下是取自旧框架的示例:

(旧系统中的线程性能细分) 在此图表中,每一行代表一个线程,X轴表示时间。不同的逻辑任务或实体用不同颜色表示。白色条显示每个排序器逻辑块在其分配线程中的运行时间。它们上方的红色条代表该帧中排序器任务所花费的总时间——约3.6毫秒。同时,整个逻辑帧耗时约22毫秒。
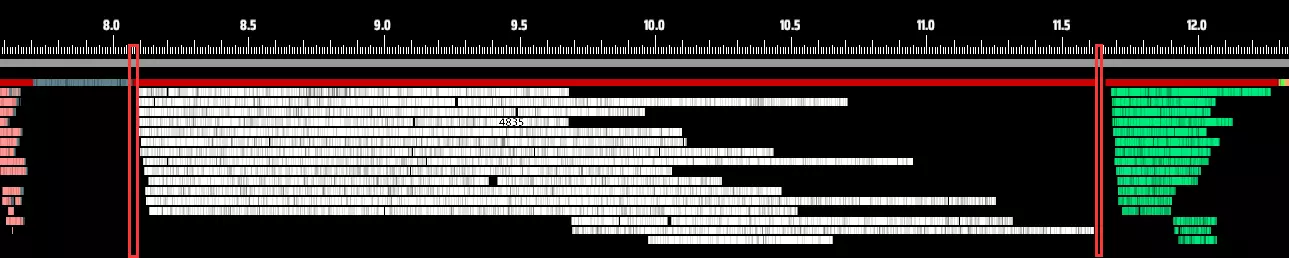
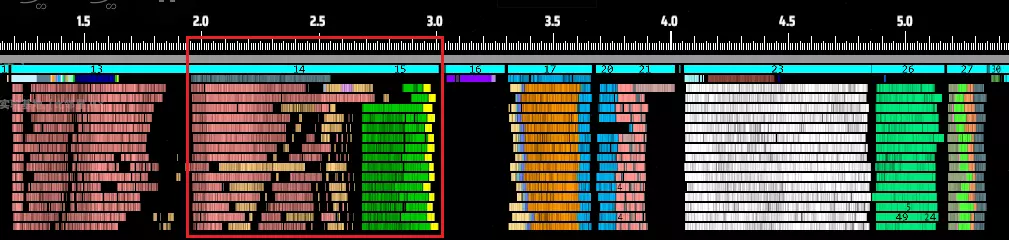
(红色方框标记了从分拣机启动到分拣完成的总时间。) 放大后,我们可以发现一些明显的问题。最显著的是,线程并非同时开始或结束工作,呈现出一种交错、不协调的执行状态。
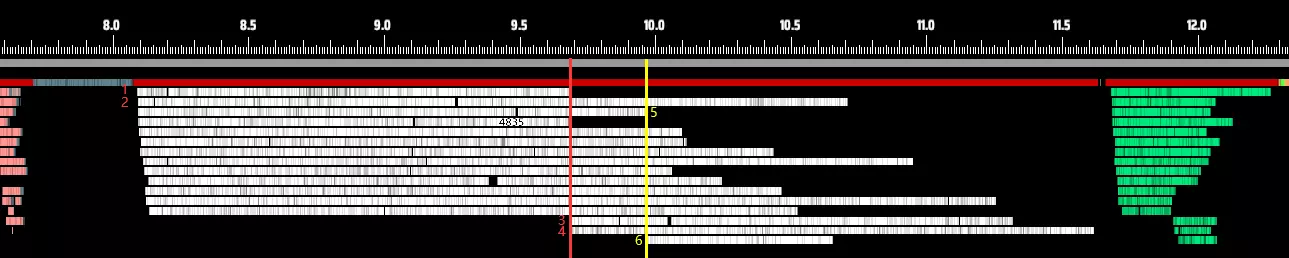
(此处,线程1、2、5首先完成——只有在此时,线程3、4、6才开始工作) 这种情况的发生可能有多种原因。有时,系统需要运行其他程序,其中一些进程可能具有高优先级,会占用CPU资源,从而导致游戏逻辑无法充分利用所有可用核心。 或者,可能某个线程正在运行一段耗时较长的逻辑。在这种情况下,操作系统可能会检测到活动线程数量较少,并且看到部分核心处于空闲状态,为了省电,可能会选择关闭一些核心——这进一步降低了多线程效率。 简而言之,操作系统级别的线程和核心自动调度是一个黑箱,往往会导致可用核心未被充分利用。问题并非简单的“16核当作15核使用,性能就下降1/16”。实际上,如果有任何一个线程因上述原因落后,其他所有线程都必须等待它完成,从而拖累整体性能。以下方图表为例,实际CPU任务执行时间(白色所示)可能不到总可用处理窗口的三分之二。

(黄色区域突出显示了CPU利用率显著不足的区域。) 即使调度不是问题,我们从图表中也能清晰地看到,不同线程完成同一类型任务所花费的时间差异极大。实际上,即便所有线程都未延迟启动,最快的线程完成任务的时间也可能仅为最慢线程的一半。

现在来看看处理阶段之间的过渡。在一个阶段结束和下一个阶段开始之间存在明显的间隔。这是因为系统仅使用阻塞锁来协调阶段过渡。这些锁可能会带来高达50微秒的开销,在这种级别的性能优化中,这是相当显著的。 全新多线程系统已上线! 为了最大限度地提高CPU利用率,我们废弃了旧框架,从零开始构建了全新的多线程系统和逻辑管道。 在全新的多线程系统中,每个核心都被充分发挥其潜力。以下是撰写本文时新系统的性能快照:

白色分拣条现在紧密排列。开始和结束时间几乎完全一致——非常完美!时间成本降至约2.4毫秒(同一存档下)。总逻辑时间从22毫秒降至11.7毫秒,提升了88%(仅逻辑帧效率)。这比将CPU从14400F升级到14900K还要好!以下是性能大幅提升的原因分析: 1. **自定义核心绑定**:在旧的多线程框架中,线程未绑定到特定CPU核心。操作系统通过不透明的调度机制自动分配核心,这往往导致核心利用率低下。现在玩家可以手动将线程绑定到特定核心,从而避免系统调度程序的这些“意外操作”。

(放大对比显示,新框架<右侧>不再像旧版本<左侧>那样出现线程排队而核心闲置的情况) 2. **动态任务分配**:即使启用了核心绑定,任务分配不均或核心性能差异仍可能导致瓶颈。部分核心可能在处理其他进程,从而延迟线程启动。为解决此问题,我们引入了动态任务分配机制。 其工作原理如下:任务最初会被平均分配。随后,任何提前完成任务的线程会从最繁忙的线程中“窃取”一半剩余工作负载。此循环会持续进行,直到所有线程的工作负载均不超过设定阈值。这一机制在最大程度减少重新分配开销的同时,避免了“一个核心苦苦支撑,其他七个核心袖手旁观”的情况。如下所示,即使某个线程启动较晚,现在所有线程也几乎能同时结束。
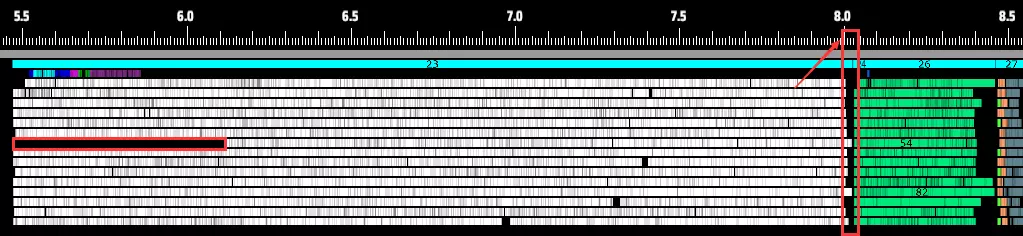
(尽管偶尔会出现启动延迟,但现在所有线程都能协同完成计算) 3. **更灵活的框架设计**:不再采用旧有的“一阶段一任务”设计,我们现在将所有逻辑归类为不同的任务类型,并可在一个阶段内自由组合。这使得单个核心能在同一阶段同时处理多种类型的逻辑。下方黄色高亮部分展示了交通监控器、喷涂机和物流站输出的并行运行情况:
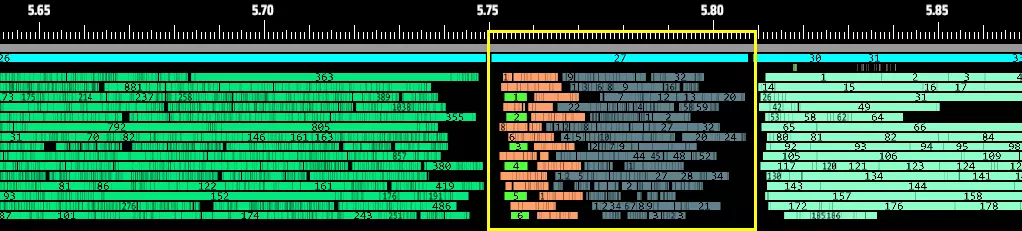
(交通监控器/喷涂机/物流站货物输出逻辑的并行执行时间现在小于0.1毫秒)

(此前为单线程时,此逻辑耗时约0.6毫秒) 得益于这种灵活性,即便是过去受限于主线程的逻辑,现在也能实现交错运行。例如,蓝色部分(红色箭头所示)为矩阵实验室(研究)逻辑——虽然仍在主线程中,但现在它能与装配机及其他设施并发运行,在无冲突的情况下充分利用CPU核心。
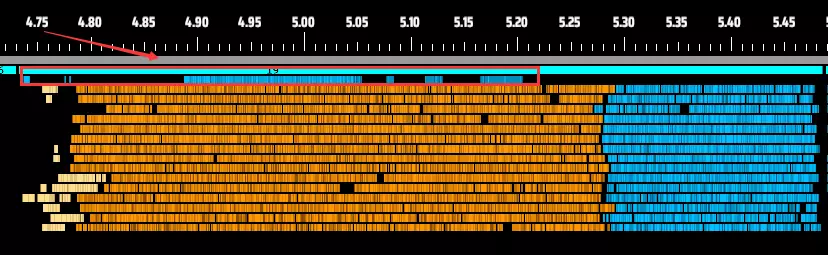
(比等待其他任务完成更灵活) 上述图表还展示了混合动态分配和静态分配的任务能够让所有线程同时完成。我们有策略地将可动态分配的任务放在静态任务之后,以填补CPU的空闲时间。
(在更新敌方炮塔/暗雾单位的同时更新电网,会利用之前闲置的CPU周期) 4. **增强线程同步**:旧系统中,主线程在各阶段之间的响应时间需要0.02-0.03毫秒,新阶段启动还需额外时间。如图所示,分拣器到传送带的阶段转换耗时约0.065毫秒。新系统将这一时间缩短至6.5微秒,速度提升10倍。

(新框架的等待时间<左侧>比旧框架<右侧>显著缩短) 我们采用了更快的自旋锁(约10纳秒)并结合混合自旋-阻塞模式:自旋锁用于超快速操作,阻塞锁用于CPU密集型任务。这种平衡的方法有效消除了各阶段之间可见的“间隙”。如快照所示,现在的最终过渡效果更加流畅自然。 当然,新的多线程系统仍有改进空间。我们当前的线程分配策略将通过持续测试不断优化,以更好地适应不同的CPU配置。此外,游戏逻辑的许多部分仍有待迁移至新的多线程框架中。为了帮助我们推进工作,我们即将推出一个公开测试分支。在此版本中,我们为玩家提供了多种可自定义选项,以便手动配置线程分配和同步策略。这将使我们能够收集有关系统在各种真实硬件和软件环境中运行表现的宝贵数据,这些关键反馈将指导未来的优化工作。

(高级多线程配置界面) 由于我们已完全重建了游戏的核心逻辑管道,现在许多不同类型的任务可以并行运行——例如,更新电网和执行物流站货物输出现在可以同时进行。由于这项架构革新,旧版游戏内统计面板中显示的CPU性能数据已不再准确或有意义。在正式推出更新后的多线程系统之前,我们也需要对游戏的这部分进行全面改进。我们还在开发一款全新的性能分析工具,它将让玩家能够清晰地实时可视化新逻辑管道的运行方式和性能表现。
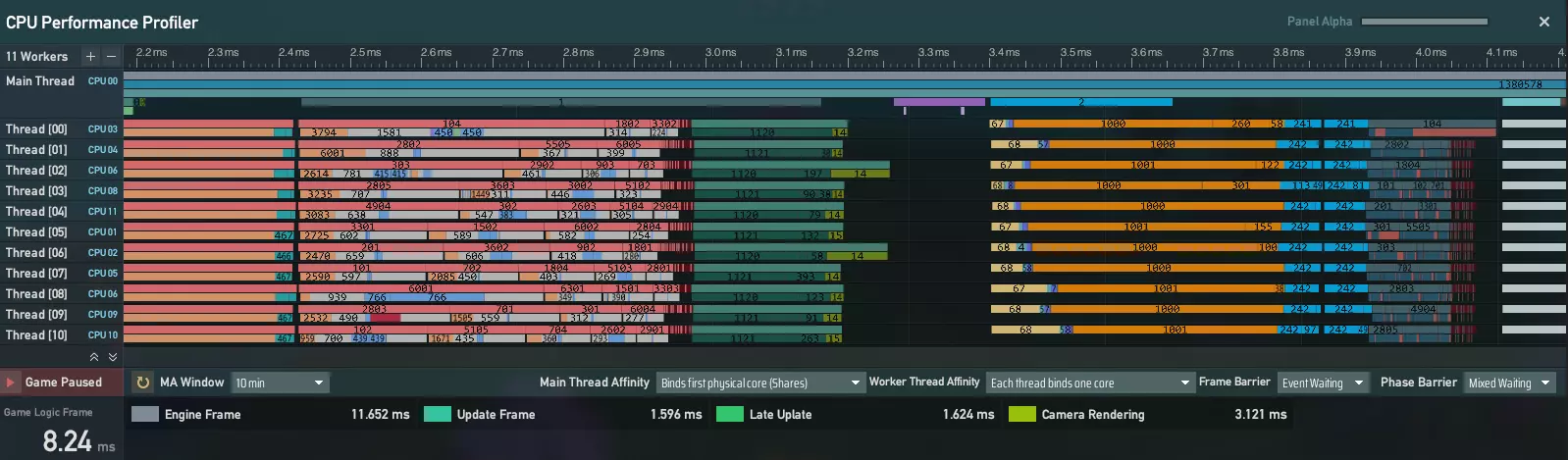
(我们知道大家会喜欢那些酷炫的图表——别担心,我们马上就会为大家呈现!) 以上就是今天的开发者日志内容。非常感谢大家的阅读!我们计划在未来几周内开放公开测试分支,所有当前玩家都可以直接参与。希望大家能来体验一番,帮助我们在不同硬件条件下验证新系统的性能和稳定性。你们的参与对于多线程系统顺利、成功地正式发布至关重要。届时见,再次感谢大家参与这段旅程! 结束